随着深度学习模型越来越复杂,训练该模型需要消耗大量的计算资源,本文纪录一些在网络架构设计上加速的一些方法。
1 x 1 convolution
该方法如下图:
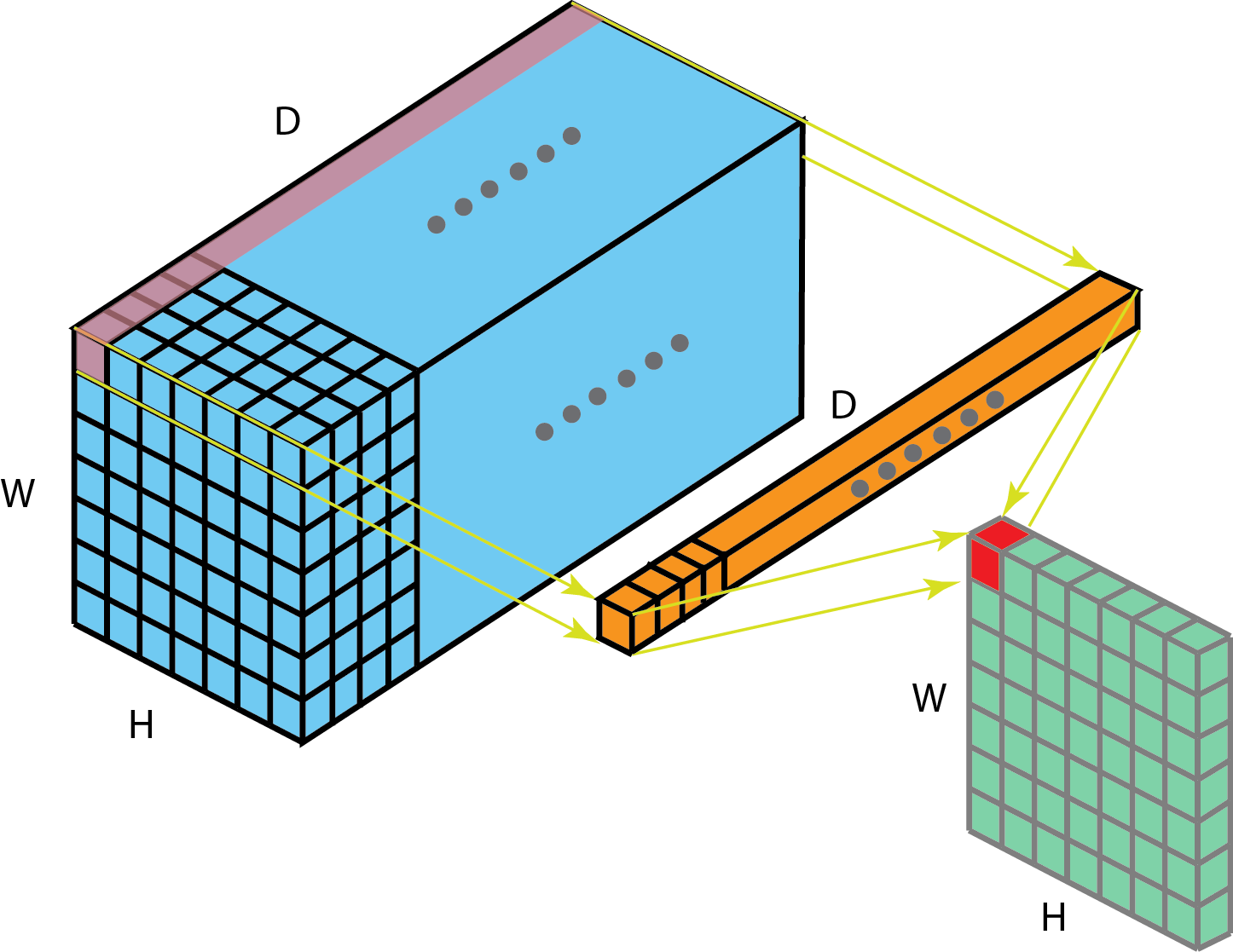 1 x 1convolution 的优点有:
1 x 1convolution 的优点有:
- Dimensionality reduction for efficient computations
- Efficient low dimensional embedding, or feature pooling
- Applying nonlinearity again after convolution
Spatially Separable Convolutions
该方法在mobileNet使用,方法如下图:
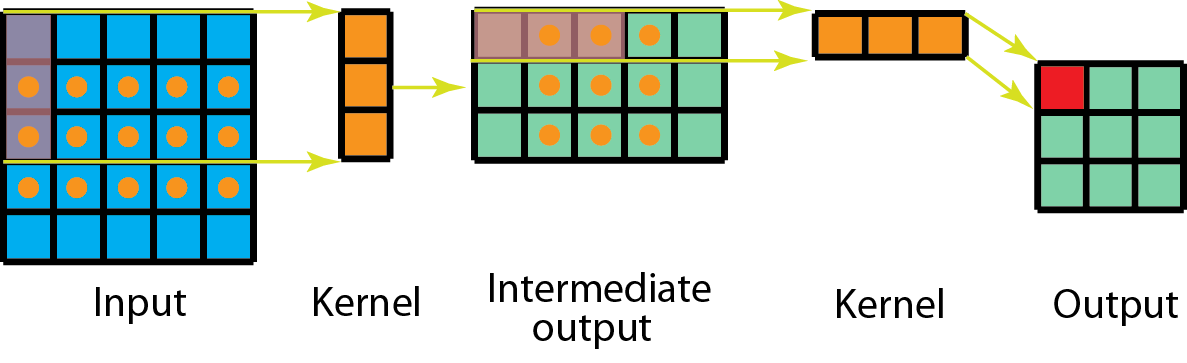
利用类似矩阵分解的方法,将矩阵用两个向量相乘表示

优点:
- 降低计算量
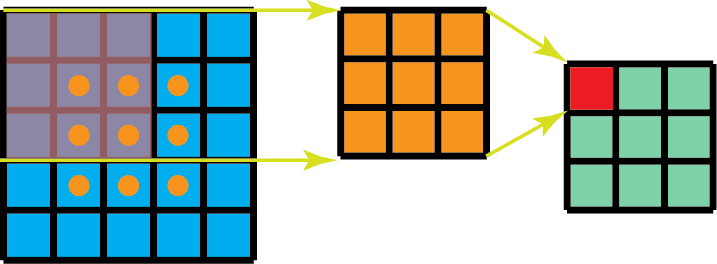
Depthwise Separable Convolutions
该方法常用于深度学习(eg. MobileNet, Xception),该方法由两部分组成: depthwise convolutions 和 1x1 convolutions.
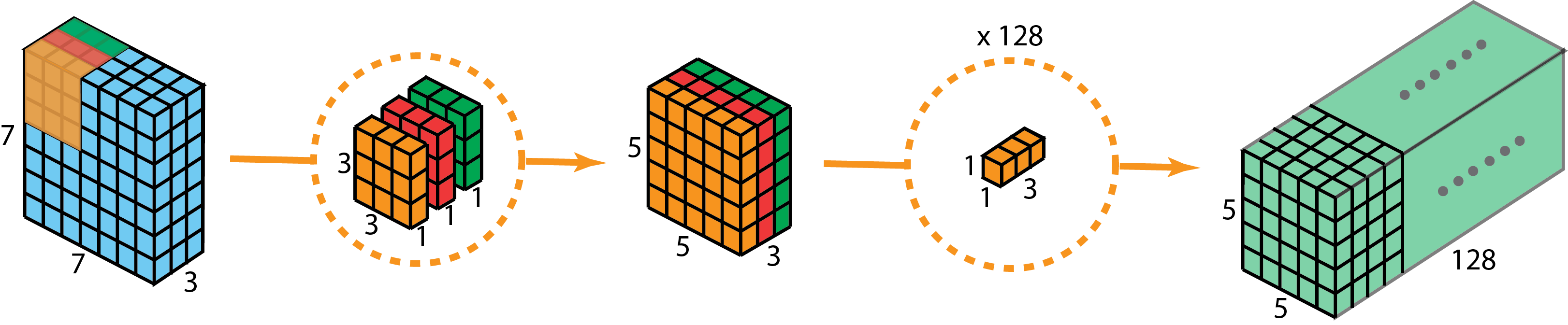
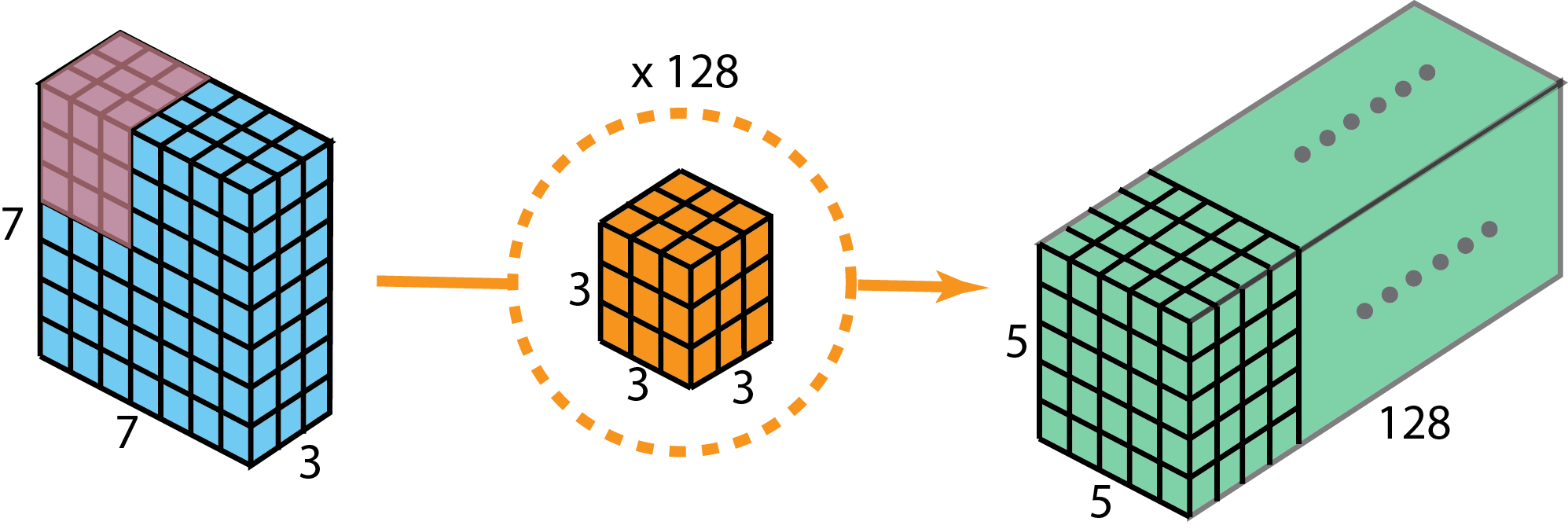
优点:
- 大幅降低计算量(约可以降低h的2次方倍的计算量,h为卷积核的大小,eg. 3x3, 5x5)
缺点:
- 降低了模型的表示能力,可能导致sub-optimal
Grouped Convolution
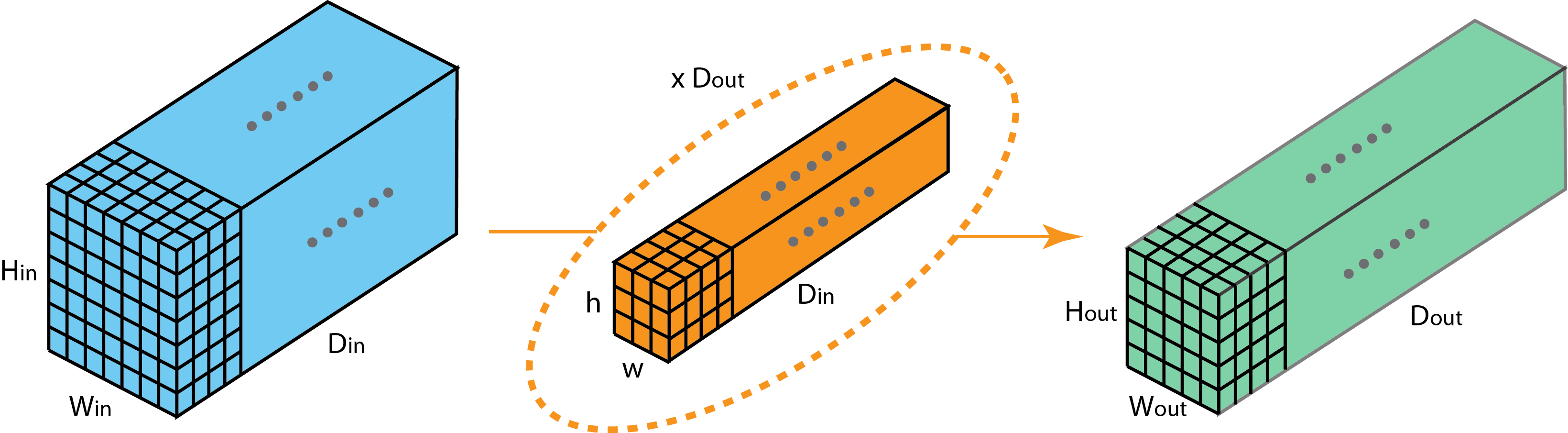
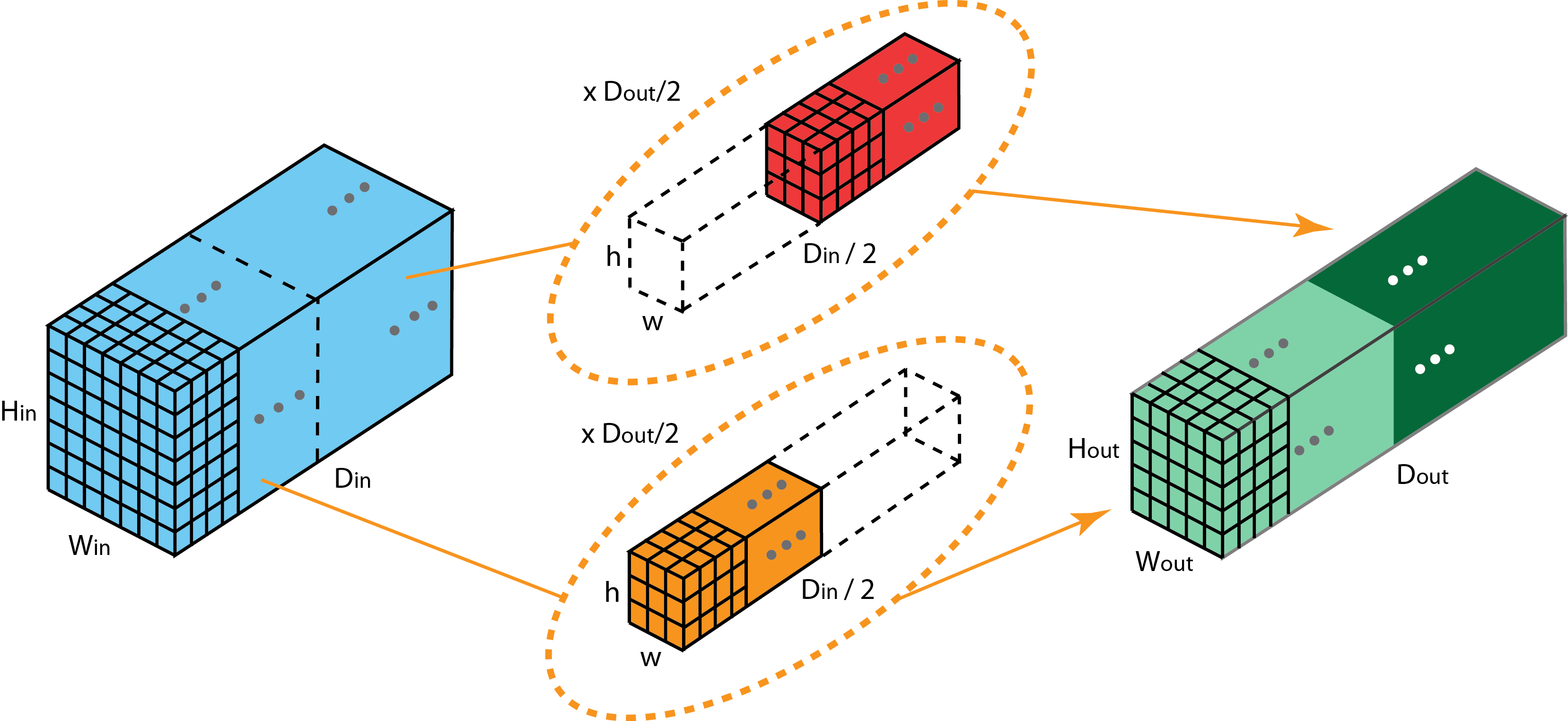 将卷积核分成两个组,分别负责一半的输入数据输出一半的数据,该方法可以用于模型并行在多个GPU上训练,并且大幅的减少了模型参数,还有文章说该方法对模型性能有所提升。
将卷积核分成两个组,分别负责一半的输入数据输出一半的数据,该方法可以用于模型并行在多个GPU上训练,并且大幅的减少了模型参数,还有文章说该方法对模型性能有所提升。
Shuffled Grouped Convolution
shuffled grouped convolution 包含了 grouped convolution 和 channel shuffling.
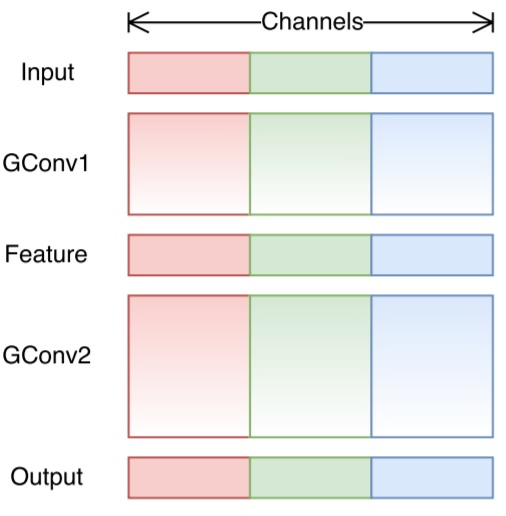 在Grouped convolution 中存在一个问题,各个分组卷积中处理的只是局部的输入数据的信息,只能从特定的一些特征中学习从而导致信息在各组卷积中阻隔了。所以引入 channel shuffling.
在Grouped convolution 中存在一个问题,各个分组卷积中处理的只是局部的输入数据的信息,只能从特定的一些特征中学习从而导致信息在各组卷积中阻隔了。所以引入 channel shuffling.
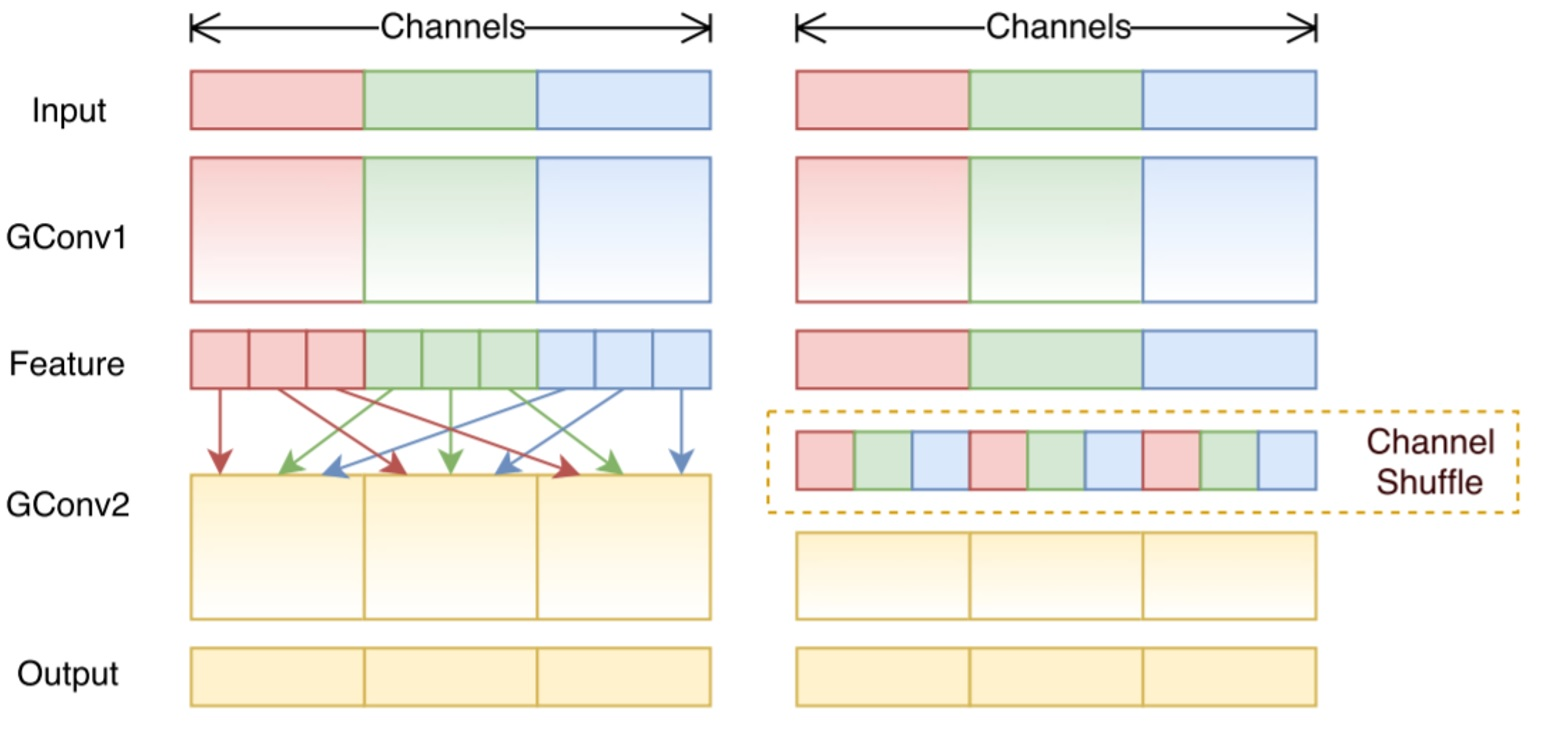
ShuffleNet V2
背景:
在shufflenet V2 文中作者指出一般设计高效网络时如:ShuffleNet v1和MobileNet v2 时都使用FLOPs这一间接的测量手段来衡量运行速度。虽然这部分占据了大部分的时间,但是I/O, data shuffle 和 element-wise operations(AddTensor, ReLU, etc)也耗费了大量的时间,所以只考虑FLOPs衡量时间是不精确的。
经过实验作者得到设计高效网络的四个方向:
- use ”balanced“ convolutions (equal channel width);
- 即卷积层的输入特征通道数与输出特征通道数尽可能相等;
- be aware of the cost of using group convolution;
- 即group convolution可以减少FLOPs,但是增加了MAC(memory access cost),所以要恰当的使用group convolution;
- reduce the degree of fragmentation;
- 因为Network fragmentation 会降低并行化
- reduce element-wise operations
- 这部分操作FLOPs很小,但是需要大量MAC
- 这部分操作FLOPs很小,但是需要大量MAC
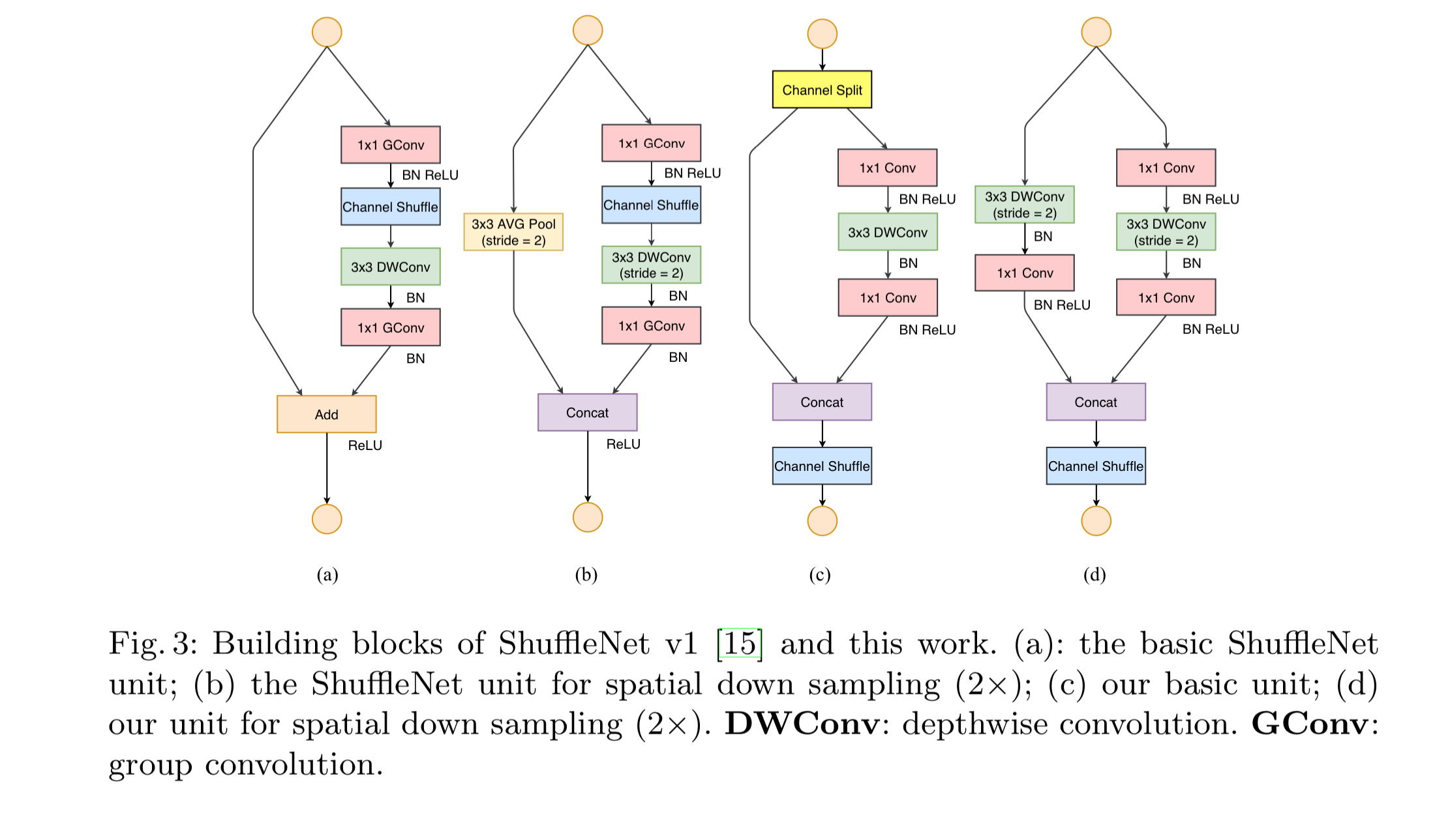
网络设计
At the beginning of each unit, the input of c feature channels are split into two branches with c − c′ and c′ channels, respectively. Following G3, one branch remains as identity. The other branch consists of three convolutions with the same input and output channels to satisfy G1. The two 1 × 1 convolutions are no longer group-wise. This is partially to follow G2, and partially because the split operation already produces two groups. After convolution, the two branches are concatenated. So, the number of channels keeps the same (G1). The same “channel shuffle” is then used to enable information communication between the two branches.
After the shuffling, the next unit begins. Note that the “Add” operation in ShuffleNet v1 no longer exists. Element-wise operations like ReLU and depth- wise convolutions exist only in one branch. Also, the three successive element- wise operations, “Concat”, “Channel Shuffle” and “Channel Split”, are merged into a single element-wise operation. These changes are beneficial according to G4.