static 静态成员变量不能在类的内部初始化。在类的内部只是声明,定义必须在类定义体的外部,通常在类的实现文件中初始化
1
2
3
4
5
6
7
class foo {
public :
foo ();
private :
static int i ;
};
int foo :: i = 20 ;
const 成员变量不能在类定义处初始化,只能通过构造函数初始化列表进行,并且必须有构造函数。
1
2
3
4
5
6
7
8
class foo {
public :
foo () : i ( 100 ){}
private :
const int i = 100 ; //error!!!
};
//或者通过这样的方式来进行初始化
foo :: foo () : i ( 100 ){}
当类成员包含其他类时,所包含的成员类会在初始化列表处进行初始化。如果没有显式提供初始化列表的初始化方式,则会调用默认无参数的构造函数。如果在构造函数内部进行成员类的初始化,则会出现两次该成员类构造函数的调用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
#include <iostream>
using namespace std ;
class A {
public :
A () {
val_ = 0 ;
cout << "A is constructed!" << endl ;
}
A ( int a ) {
val_ = a ;
cout << "A is constructed!" << endl ;
}
int val_ ;
};
class B {
private :
A a ;
public :
B () : a ( A ( 5 )) {
cout << "B is constructed!" << endl ;
}
A get_A () {
return a ;
}
};
int main () {
B b ;
cout << ( b . get_A ()). val_ << endl ;
return 0 ;
}
// 输出:
// A is constructed!
// B is constructed!
// 5
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <iostream>
using namespace std ;
class A {
public :
A () {
a = 0 ;
}
int & get_a () {
return a ;
}
private :
int a ;
};
int main ()
{
A a1 ;
int b = a1 . get_a (); // 修改b不能更改类成员变量a的值
int & b1 = a1 . get_a (); // 修改b1能更改类成员变量a的值
return 0 ;
}
纯虚函数是一种特殊的虚函数,在许多情况下,在基类中不能对虚函数给出有意义的实现,而把它声明为纯虚函数,它的实现留给该基类的派生类去做。
1
2
3
4
5
class <类名 >
{
virtual < 类型 >< 函数名 > ( < 参数表 > ) = 0 ;
…
};
凡是含有纯虚函数的类叫做抽象类。这种类不能声明对象,只是作为基类为派生类服务。除非在派生类中完全实现基类中所有的的纯虚函数,否则,派生类也变成了抽象类,不能实例化对象。包含纯虚函数的类叫做抽象类( 也叫接口类) , 抽象类不能实例化出对象。
当一个子类传入一个函数时,函数上的参数声明为其父类,在函数内对该父类进行操作,函数返回后,只会更改这个子类内父类的部分其余不变。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
#include <iostream>
using namespace std ;
class A {
public :
A () {
val_1 = 1 ;
}
int get_val_1 () {
return val_1 ;
}
void set_val_1 ( int val ) {
val_1 = val ;
}
private :
int val_1 ;
};
class B : public A {
public :
B () {
val_2 = 2 ;
}
int get_val_2 () {
return val_2 ;
}
void set_val_2 ( int val ) {
val_2 = val ;
}
private :
int val_2 ;
};
void func ( A & a ) {
a . set_val_1 ( 5 );
}
int main ()
{
B b ;
func ( b );
cout << b . get_val_1 () << " " << b . get_val_2 () << endl ;
return 0 ;
}
通过声明vitual虚函数在父类,子类继承父类重写虚函数。需注意使用该方法作为多态时,需要使用父类的指针。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <iostream>
#include <vector>
using namespace std ;
class Kernel {
public :
virtual void operator () ( int & a , int & b , int & c ) {}
};
class RBF : public Kernel {
public :
virtual void operator () ( int & a , int & b , int & c ) {
c = a * b ;
}
};
class Test {
public :
Test ( Kernel & kernel ) {
kernel_ = & kernel ;
}
void print () {
int a = 1 , b = 5 , c ;
( * kernel_ )( a , b , c );
cout << c << endl ;
}
private :
Kernel * kernel_ ;
};
int main ()
{
RBF rbf ;
Test test ( rbf );
test . print ();
return 0 ;
}
尽管在子类重写的函数中使用自身的成员变量与函数,转换后的父类指针调用重写的方法可以成功。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
#include <cstdio>
#include <cstdlib>
#include <iostream>
#include <fstream>
#include <vector>
#include <map>
#include <memory>
#include <string>
#include <cmath>
using namespace std ;
class A {
public :
int count ;
A () {
count = 1 ;
}
virtual void com ( int a ) = 0 ;
};
class B : public A {
public :
B () {
b = 4 ;
}
void add ( int c ) {
this -> count += c ;
}
void com ( int a ) {
count += a ;
add ( b );
}
int b ;
};
void func ( A & a ) {
a . com ( 3 );
cout << a . count << endl ;
}
int main ( int argc , char * argv []) {
B b ;
func ( b );
vector < A *> p ;
p . push_back ( & b );
p [ 0 ] -> com ( 3 );
}
基类A有友元类B,A的继承类C依旧有友元类B
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
#include <iostream>
using namespace std ;
class B ;
class A
{
int a ;
public :
A ( int x = 0 ){ a = x ; }
friend class B ;
};
class C : public A //通过继承,A的友员类B成了派生类C的友员类
{
public :
C ( int x ) : A ( x ){}
};
class B
{
public :
void fun ( A & ob ) { cout << ob . a << endl ; }
void fun2 ( C & ob ) { cout << ob . a << endl ; }
};
int main ()
{
C c ( 55 );
B b ;
b . fun ( c );
b . fun2 ( c );
}
基类A是类B的友元类,但是A的继承类C不是B的友元类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <iostream>
using namespace std ;
class B ;
class A
{
int a ;
public :
A ( int x = 0 ) { a = x ; }
friend class B ;
};
class B
{
int b ;
public :
void fun ( A & ob ){ cout << ob . a << endl ;}
};
class C : public B
{
public :
// void fun2(A& ob){ cout <<ob.a <<endl;} //派生类新加的函数却不能访问A,此句会报错
};
int main ()
{
A a ( 55 );
C c ;
c . fun ( a ); //C是B的派生类 通过基类B的函数fun仍然可以访问
return 0 ;
}
运算符()和其它的运算符一样,重载方式一致。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
#include <iostream>
using namespace std ;
#include <iostream>
using namespace std ;
class DArrary
{
public :
DArrary (){
int i = 0 ;
int num = 0 ;
for ( i = 0 ; i < 9 ; i ++ )
arr [ i / 3 ][ i % 3 ] = num ++ ;
}
void display ( void ){
int i = 0 ;
for ( i = 0 ; i < 9 ; i ++ )
cout << arr [ i / 3 ][ i % 3 ] << " " ;
cout << endl ;
}
//operator overload : () Multiple Parameters
int & operator ()( int a , int b )
{
return arr [ a ][ b ];
}
//operator overload : () Singal Parameter
int & operator ()( int a )
{
return arr [ a / 3 ][ a % 3 ];
}
//operator overload : () None Parameter
int & operator ()( void )
{
return arr [ 0 ][ 0 ];
}
private :
int arr [ 3 ][ 3 ];
};
int main ( void )
{
DArrary arr ();
arr . display ();
cout << arr ( 0 , 0 ) << endl ; //取值
cout << arr ( 2 , 2 ) << endl ; //取值
arr ( 0 , 0 ) = 11 ; //赋值
arr ( 2 , 2 ) = 22 ; //赋值
cout << arr ( 0 , 0 ) << endl ;
cout << arr ( 2 , 2 ) << endl ;
cout << arr ( 7 ) << endl ; //取值
arr ( 7 ) = 33 ; //赋值
cout << arr ( 7 ) << endl ;
cout << arr () << endl ;
arr () = 111 ;
arr . display ();
return 0 ;
}
对于模板类的继承类中如果要使用父类的成员变量需要加上this->或者parent_class_name<T>::(否则会出现找不到成员变量或函数的错误)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <iostream>
using namespace std ;
template < class T >
class A {
public :
A ( int val ) {
val_ = val ;
}
protected :
T val_ ;
};
template < class T >
class B : public A < T > {
public :
B ( int val ) : A < T > ( val ) { }
void show () {
// cout << val_ << endl; // Error
cout << this -> val_ << endl ; // Right
cout << A < T >:: val_ << endl ; // Right
}
};
int main ( void )
{
B < int > b ( 6 );
b . show ();
return 0 ;
}
默认模板参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <iostream>
using namespace std ;
template < class T = int >
class A {
public :
A ( int val ) {
val_ = val ;
}
protected :
T val_ ;
};
int main (){
A <> a ;
}
模板特化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
// 首先,要写出模板的一般形式(原型)
template < typename T > class AddFloatOrMulInt
{
static T Do ( T a , T b )
{
return 0 ;
}
};
// 其次,我们要指定T是int时候的代码,这就是特化:
template <> class AddFloatOrMulInt < int >
{
public :
static int Do ( int a , int b ) //
{
return a * b ;
}
};
// 再次,我们要指定T是float时候的代码:
template <> class AddFloatOrMulInt < float >
{
public :
static float Do ( float a , float b )
{
return a + b ;
}
};
void foo ()
{
// 这里面就不写了
}
1
2
3
4
5
6
7
8
9
10
// 类模板
template < class T1 , class T2 >
class A {
T1 data1 ;
T2 data2 ;
};
template < class T2 >
class A < int , T2 > {
...
};
偏特化也是为了给自定义一个参数集合的模板,但偏特化后的模板需要进一步的实例化才能形成确定的签名。 值得注意的是函数模板不允许偏特化。
在重载输出输入运算符的时候,只能采用全局函数的方式,即友元函数的形式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <iostream>
using namespace std ;
class Distance
{
private :
int feet ; // 0 到无穷
int inches ; // 0 到 12
public :
// 所需的构造函数
Distance (){
feet = 0 ;
inches = 0 ;
}
Distance ( int f , int i ){
feet = f ;
inches = i ;
}
friend ostream & operator << ( ostream & output , const Distance & D )
{
output << "F : " << D . feet << " I : " << D . inches ;
return output ;
}
friend istream & operator >> ( istream & input , Distance & D )
{
input >> D . feet >> D . inches ;
return input ;
}
};
int main ()
{
Distance D1 ( 11 , 10 ), D2 ( 5 , 11 ), D3 ;
cout << "Enter the value of object : " << endl ;
cin >> D3 ;
cout << "First Distance : " << D1 << endl ;
cout << "Second Distance :" << D2 << endl ;
cout << "Third Distance :" << D3 << endl ;
return 0 ;
}
拷贝构造函数会被调用的情况是:
声明新对象
按值将参数传递给函数时
或按值从函数返回值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
#include <iostream>
using namespace std ;
class A {
public :
A (){
val_ = 0 ;
}
A ( int val ){
val_ = val ;
}
A ( const A & a ) {
cout << "come in copy constructor" << endl ;
val_ = a . val_ ;
}
A & operator = ( A & a ) {
this -> val_ = a . val_ ;
return * this ;
}
int val_ ;
};
void func ( A a ) { // 调用一次拷贝构造函数
}
A func1 ( A a ) { // 调用两次拷贝构造函数
return a ;
}
A func2 () { // 不会调用拷贝构造函数
A a ( 1 );
return a ;
}
int main ()
{
A a1 ( 1 );
A a2 = a1 ; //调用拷贝构造函数
A a3 ;
a3 = a1 ; // 不会调用拷贝构造函数,调用的是‘=’运算符函数
return 0 ;
}
<typeinfo>我们可以使用typeid()来对实例对象的类进行判断比较, 并且还可以输出其属于的类名,例子如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
#include <iostream>
#include <typeinfo>
#include <string>
#include <utility>
class person
{
public :
person ( std :: string && n ) : _name ( n ) {}
virtual const std :: string & name () const { return _name ; }
private :
std :: string _name ;
};
class employee : public person
{
public :
employee ( std :: string && n , std :: string && p ) :
person ( std :: move ( n )), _profession ( std :: move ( p )) {}
const std :: string & profession () const { return _profession ; }
private :
std :: string _profession ;
};
void somefunc ( const person & p )
{
if ( typeid ( employee ) == typeid ( p ))
{
std :: cout << p . name () << " is an employee " ;
auto & emp = dynamic_cast < const employee &> ( p );
std :: cout << "who works in " << emp . profession () << '\n' ;
}
if ( typeid ( person ) == typeid ( p )) {
std :: cout << "it is a preson class" << std :: endl ;
}
}
int main ()
{
employee paul ( "Paul" , "Economics" );
somefunc ( paul );
std :: cout << typeid ( paul ). name () << std :: endl ;
}
// 输出为:
// Paul is an employee who works in Economics
// 8employee
注意:在《clean code》书中对于基于typeid()来进行类判断的操作的代码是禁止的,因为这样抵消了多态的好处。
函数型对象(其实就是一个类重载了操作符() )。根据运算符()是无参数、一个参数还是两个参数,可以称为生成器、一元函数或二元函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
// 生成器
class IncreasingNumberGenerator {
public :
int operator ()() noexcept { return number ++ ; }
private :
int number { 0 };
};
int main () {
IncreasingNumberGenerator numberGenerator { };
std :: cout << numberGenerator () << std :: endl ;
std :: cout << numberGenerator () << std :: endl ;
std :: cout << numberGenerator () << std :: endl ;
return 0 ;
}
// 伪随机数生成器
#include <random>
template < typename NUMTYPE >
class RandomNumberGenerator {
public :
RandomNumberGenerator () {
mersenneTwisterEngine . seed ( randomDevice ());
}
NUMTYPE operator ()() {
return distribution ( mersenneTwisterEngine );
}
private :
std :: random_device randomDevice ;
std :: uniform_int_distribution < NUMTYPE > distribution ;
std :: mt19937_64 mersenneTwisterEngine ;
};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class ToSquare {
public :
constexpr int operator ()( const int value ) const noexcept {
return value * value ;
}
};
#include <algorithm>
#include <vector>
using Numbers = std :: vector < int > ;
int main () {
const std :: size_t AMOUNT_OF_NUMBERS = 100 ;
Numbers numbers ( AMOUNT_OF_NUMBERS );
// 利用一个生成器对可遍历对象进行赋值
std :: generate ( std :: begin ( numbers ), std :: end ( numbers ), IncreasingNumberGenerator ());
// 利用对所有遍历对象进行操作后赋值
std :: transform ( std :: begin ( numbers ), std :: end ( numbers ), std :: begin ( numbers ), ToSquare ()); // ...
return 0 ;
}
通过使用std::bind()可以将一个函数和特定的输入参数进行绑定,变成函数对象
1
2
3
4
5
6
7
8
9
10
11
12
#include <functional>
#include <iostream>
constexpr double multiply ( const double multiplicand , const double multiplier ) noexcept {
return multiplicand * multiplier ;
}
int main () {
const auto result1 = multiply ( 10.0 , 5.0 );
auto boundMultiplyFunctor = std :: bind ( multiply , 10.0 , 5.0 );
const auto result2 = boundMultiplyFunctor ();
std :: cout << "result1 = " << result1 << ", result2 = " << result2 << std :: endl ;
return 0 ;
}
std::bind还可以应用于率先确定部分参数(partial application), 我们使用std::bind确定了部分参数后,其余未确定的参数将使用_1, _2, _3, ...替换。
1
2
3
4
5
6
7
8
9
10
11
#include <functional>
#include <iostream>
constexpr double multiply ( const double multiplicand , const double multiplier ) noexcept {
return multiplicand * multiplier ;
}
int main () {
using namespace std :: placeholders ;
auto multiplyWith10 = std :: bind ( multiply , _1 , 10.0 );
std :: cout << "result = " << multiplyWith10 ( 5.0 ) << std :: endl ;
return 0 ;
}
高级函数是一类函数可以将其它函数作为参数,或者将函数作为返回值的函数。在C++中任何可调用的对象(callable object),比如:用std::function生成的对象、一个函数指针、一个lambda表达式、一个函数对象和任何实现了操作符()的对象都可以作为参数传递给高级函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
#include <functional>
#include <iostream>
#include <vector>
template < typename CONTAINERTYPE , typename UNARYFUNCTIONTYPE >
void myForEach ( const CONTAINERTYPE & container , UNARYFUNCTIONTYPE unaryFunction ) {
for ( const auto & element : container ) {
unaryFunction ( element );
}
}
template < typename CONTAINERTYPE , typename UNARYOPERATIONTYPE >
void myTransform ( CONTAINERTYPE & container , UNARYOPERATIONTYPE unaryOperator ) {
for ( auto & element : container ) { element = unaryOperator ( element );
} }
template < typename NUMBERTYPE > class ToSquare {
public :
NUMBERTYPE operator ()( const NUMBERTYPE & number ) const noexcept {
return number * number ;
}
};
template < typename TYPE >
void printOnStdOut ( const TYPE & thing ) {
std :: cout << thing << ", " ;
}
int main () {
std :: vector < int > numbers { 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 };
myTransform ( numbers , ToSquare < int > ());
std :: function < void ( int ) > printNumberOnStdOut = printOnStdOut < int > ;
myForEach ( numbers , printNumberOnStdOut );
return 0 ;
}
C++内置的是三个好用的高级函数:
·<algorithm>中的std::transform
实现将函数应用于列表中的所有元素
<algorithm>中的std::remove_if
实现删除不满足条件的列表元素
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#include <algorithm>
#include <iostream>
#include <string>
#include <vector>
class IsPalindrome { public :
bool operator ()( const std :: string & word ) const {
const auto middleOfWord = begin ( word ) + word . size () / 2 ;
return std :: equal ( begin ( word ), middleOfWord , rbegin ( word ));
}
};
int main () {
std :: vector < std :: string > someWords { "dad" , "hello" , "radar" , "vector" , "deleveled" , "foo" ,
"bar" , "racecar" , "ROTOR" , "" , "C++" , "aibohphobia" };
someWords . erase ( std :: remove_if ( begin ( someWords ), end ( someWords ), IsPalindrome ()), end ( someWords ));
std :: for_each ( begin ( someWords ), end ( someWords ), []( const auto & word ) { std :: cout << word << "," ; });
return 0 ;
}
<numeric>中的std::accumulate
实现对列表中的原素使用二元函数
1
2
3
4
5
6
7
8
9
#include <numeric>
#include <iostream>
#include <vector>
int main () {
std :: vector < int > numbers { 12 , 45 , - 102 , 33 , 78 , - 8 , 100 , 2017 , - 110 };
const int maxValue = std :: accumulate ( begin ( numbers ), end ( numbers ), 0 ,
[]( const int value1 , const int value2 ) { return value1 > value2 ? value1 : value2 ;});
std :: cout << "The highest number is: " << maxValue << std :: endl ; return 0 ;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
void UseRawPointer ()
{
// Using a raw pointer -- not recommended.
Song * pSong = new Song ( L "Nothing on You" , L "Bruno Mars" );
// Use pSong...
// Don't forget to delete!
delete pSong ;
}
void UseSmartPointer ()
{
// Declare a smart pointer on stack and pass it the raw pointer.
unique_ptr < Song > song2 ( new Song ( L "Nothing on You" , L "Bruno Mars" ));
// Use song2...
wstring s = song2 -> duration_ ;
//...
} // song2 is deleted automatically here.
智能指针是你在堆栈上声明的类模板,并可通过使用指向某个堆分配的对象的原始指针进行初始化。 在初始化智能指针后,它将拥有原始的指针。 这意味着智能指针负责删除原始指针指定的内存。 智能指针析构函数包括要删除的调用,并且由于在堆栈上声明了智能指针,当智能指针超出范围时将调用其析构函数。
重要: 请始终在单独的代码行上创建智能指针,而绝不在参数列表中创建智能指针,这样就不会由于某些参数列表分配规则而发生轻微泄露资源的情况。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#include <iostream>
#include <memory>
int main () {
int * p = new int ( 10 );
std :: shared_ptr < int > a ( p );
if ( a . get () == p )
std :: cout << "a and p point to the same location \n " ;
// three ways of accessing the same address:
std :: cout << * a . get () << " \n " ;
std :: cout << * a << " \n " ;
std :: cout << * p << " \n " ;
return 0 ;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#include <iostream>
#include <memory>
int main () {
std :: shared_ptr < int > sp ; // empty
sp . reset ( new int ); // takes ownership of pointer
* sp = 10 ;
std :: cout << * sp << '\n' ;
sp . reset ( new int ); // deletes managed object, acquires new pointer
* sp = 20 ;
std :: cout << * sp << '\n' ;
sp . reset (); // deletes managed object
return 0 ;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
std :: unique_ptr < int > up1 ( new int ( 11 )); // 无法复制的unique_ptr
//unique_ptr<int> up2 = up1; // err, 不能通过编译
std :: cout << * up1 << std :: endl ; // 11
std :: unique_ptr < int > up3 = std :: move ( up1 ); // 现在p3是数据的唯一的unique_ptr
std :: cout << * up3 << std :: endl ; // 11
//std::cout << *up1 << std::endl; // err, 运行时错误
up3 . reset (); // 显式释放内存
up1 . reset (); // 不会导致运行时错误
//std::cout << *up3 << std::endl; // err, 运行时错误
std :: unique_ptr < int > up4 ( new int ( 22 )); // 无法复制的unique_ptr
up4 . reset ( new int ( 44 )); //"绑定"动态对象
std :: cout << * up4 << std :: endl ; // 44
up4 = nullptr ; //显式销毁所指对象,同时智能指针变为空指针。与up4.reset()等价
std :: unique_ptr < int > up5 ( new int ( 55 ));
int * p = up5 . release (); //只是释放控制权,不会释放内存
std :: cout << * p << std :: endl ;
//cout << *up5 << endl; // err, 运行时错误
delete p ; //释放堆区资源
unique_ptr持有对对象的独有权,同一时刻只能有一个unique_ptr指向给定对象(通过禁止拷贝语义、只有移动语义来实现)。
unique_ptr指针本身的生命周期:从unique_ptr指针创建时开始,直到离开作用域。离开作用域时,若其指向对象,则将其所指对象销毁(默认使用delete操作符,用户可指定其他操作)。
忘记 delete
1
2
3
4
5
6
7
8
9
10
11
12
class Box {
public :
Box () : w ( new Widget ())
{}
~ Box ()
{
// 忘记 delete w
}
private :
Widget * w ;
};
异常安全
1
2
3
4
5
6
void process ()
{
Widget * w = new Widget ();
w -> do_something (); // 可能会发生异常
delete w ;
}
1
2
3
4
5
6
7
8
9
10
11
std :: shared_ptr < int > sp1 ( new int ( 22 ));
std :: shared_ptr < int > sp2 = sp1 ;
std :: cout << "cout: " << sp2 . use_count () << std :: endl ; // 2
std :: cout << * sp1 << std :: endl ; // 22
std :: cout << * sp2 << std :: endl ; // 22
sp1 . reset (); // 显示让引用计数减一
std :: cout << "count: " << sp2 . use_count () << std :: endl ; // count: 1
std :: cout << * sp2 << std :: endl ; // 22
shared_ptr允许多个该智能指针共享第“拥有”同一堆分配对象的内存,这通过引用计数(reference counting)实现,会记录有多少个shared_ptr共同指向一个对象,一旦最后一个这样的指针被销毁,也就是一旦某个对象的引用计数变为0,这个对象会被自动删除
通过vector<shared_ptr< A > > v.push_back(),share_ptr的计数会加一
#include <cstdio>
#include <cstdlib>
#include <iostream>
#include <fstream>
#include <vector>
#include <map>
#include <memory>
#include <string>
using namespace std;
class A{
public:
A() {
cout << "construct A" << endl;
}
~A() {
next_.clear();
pre_.clear();
}
A(const A& a) {
cout << "copy A" << endl;
}
void operator =(const A& a) {
cout << "= A" << endl;
}
void Next(shared_ptr<A>& a) {
next_.push_back(a);
}
void Pre(shared_ptr<A>& a) {
pre_.push_back(a);
}
vector<shared_ptr<A> > next_;
vector<shared_ptr<A> > pre_;
};
int main(int argc, char *argv[])
{
shared_ptr<A> a1(new A());
next.push_back(a1);
cout << a1.use_count() << endl; // 2
return 0;
}
使用函数void func(shared_ptr<A>& a)或者void func(shared_ptr<A> a)均会让计数加一
以下代码则会出现内存泄露,泄露的内存大小为一个类A所占用的内存,可能的原因是出现了循环引用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
#include <cstdio>
#include <cstdlib>
#include <iostream>
#include <fstream>
#include <vector>
#include <map>
#include <memory>
#include <string>
using namespace std ;
class A {
public :
A () {
cout << "construct A" << endl ;
}
~ A () {
next_ . clear ();
pre_ . clear ();
}
A ( const A & a ) {
cout << "copy A" << endl ;
}
void operator = ( const A & a ) {
cout << "= A" << endl ;
}
void Next ( shared_ptr < A >& a ) {
next_ . push_back ( a );
}
void Pre ( shared_ptr < A >& a ) {
pre_ . push_back ( a );
}
vector < shared_ptr < A > > next_ ;
vector < shared_ptr < A > > pre_ ;
};
int main ( int argc , char * argv [])
{
shared_ptr < A > a1 ( new A ());
shared_ptr < A > a2 ( new A ());
a1 -> Next ( a2 );
a2 -> Pre ( a1 );
cout << a2 . use_count () << endl ;
return 0 ;
}
解决方法
#include <cstdio>
#include <cstdlib>
#include <iostream>
#include <fstream>
#include <vector>
#include <map>
#include <memory>
#include <string>
using namespace std;
class A{
public:
A() {
cout << "construct A" << endl;
}
~A() {
next_.clear();
pre_.clear();
}
A(const A& a) {
cout << "copy A" << endl;
}
void operator =(const A& a) {
cout << "= A" << endl;
}
void Next(A* a) {
next_.push_back(a);
}
void Pre(A* a) {
pre_.push_back(a);
}
vector<A*> next_;
vector<A*> pre_;
};
int main(int argc, char *argv[])
{
shared_ptr<A> a1(new A());
shared_ptr<A> a2(new A());
a1->Next(a2.get());
a2->Pre(a1.get());
cout << a2.use_count() << endl;
return 0;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
#include <iostream>
#include <string>
#include <memory>
void check ( std :: weak_ptr < int > & wp )
{
std :: shared_ptr < int > sp = wp . lock (); // 转换为shared_ptr<int>
if ( sp != nullptr )
{
std :: cout << "still: " << * sp << std :: endl ;
}
else
{
std :: cout << "still: " << "pointer is invalid" << std :: endl ;
}
}
void mytest ()
{
std :: shared_ptr < int > sp1 ( new int ( 22 ));
std :: shared_ptr < int > sp2 = sp1 ;
std :: weak_ptr < int > wp = sp1 ; // 指向shared_ptr<int>所指对象
// std::cout << *wp << std::endl; 编译不过
std :: cout << "count: " << wp . use_count () << std :: endl ; // count: 2
std :: cout << * sp1 << std :: endl ; // 22
std :: cout << * sp2 << std :: endl ; // 22
check ( wp ); // still: 22
sp1 . reset ();
std :: cout << "count: " << wp . use_count () << std :: endl ; // count: 1
std :: cout << * sp2 << std :: endl ; // 22
check ( wp ); // still: 22
sp2 . reset ();
std :: cout << "count: " << wp . use_count () << std :: endl ; // count: 0
check ( wp ); // still: pointer is invalid
}
weak_ptr是为配合shared_ptr而引入的一种智能指针来协助shared_ptr工作,它可以从一个shared_ptr或另一个weak_ptr对象构造,它的构造和析构不会引起引用计数的增加或减少。没有重载 * 和 -> 但可以使用lock获得一个可用的shared_ptr对象
weak_ptr的使用更为复杂一点,它可以指向shared_ptr指针指向的对象内存,却并不拥有该内存,而使用weak_ptr成员lock,则可返回其指向内存的一个share_ptr对象,且在所指对象内存已经无效时,返回指针空值nullptr。
注意:weak_ptr并不拥有资源的所有权,所以不能直接使用资源。可以从一个weak_ptr构造一个shared_ptr以取得共享资源的所有权。
只在函数使用指针,但并不保存对象内容
1
2
void func ( Widget * );
void func ( const shared_ptr < Widget >& )
假如我们只需要在函数中,用这个对象处理一些事情,但不打算涉及其生命周期的管理,也不打算通过函数传参延长 shared_ptr 的生命周期。
对于这种情况,可以使用 raw pointer 或者 const shared_ptr&。
在函数中保存智能指针
1
void func ( std :: shared_ptr < Widget > ptr );
假如我们需要在函数中把这个智能指针保存起来,这个时候建议直接传值。
在类类型转换中,我们通常有两个需求,一个是将其他类型的数据转换为我们自定义类的类型,另一个是将自定义类的类型在需要的时候转换为其他的数据类型。转换构造函数能很好地满足前一个需求,针对后面一个需求,我们除了可以使用普通的成员函数进行显示转换
类型转换函数一般形式:
1
2
3
4
5
operator 目标类型 ()
{
...
return 目标类型数据 ;
}
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
class A {
public :
A ( const int x ) : _x ( x ) {}
operator int () { return _x ; }
private :
int _x ;
};
int main () {
A a ( 10 );
int res = a + 20 ;
std :: cout << res << std :: endl ;
}
有符号
按二进制形式把所有数字向右移动相应的位数,地位移出舍弃,正数,高位补0,负数,高位空位补1.
何谓伪共享?上面我们提过CPU的缓存是以缓存行为单位进行的,即除了本身所需读写的数据之外还会缓存与该数据在同一缓存行的数据,假设缓存行大小是32字节,内存中有“abcdefgh”八个int型数据,当CPU读取“d”这个数据时,CPU会将“abcdefgh”八个int数据组成一个缓存行加入到CPU缓存中。假设计算机有两个CPU:CPU1和CPU2,CPU1只对“a”这个数据进行频繁读写,CPU2只对“b”这个数据进行频繁读写,按理说这两个CPU读写数据没有任何关联,也就不会产生任何竞争,不会有性能问题,但是由于CPU缓存是以缓存行为单位进行存取的,也是以缓存行为单位失效的,即使CPU1只更改了缓存行中“a”数据,也会导致CPU2中该缓存行完全失效,同理,CPU2对“b”的改动也会导致CPU1中该缓存行失效,由此引发了该缓存行在两个CPU之间“乒乓”,缓存行频繁失效,最终导致程序性能下降,这就是伪共享。
避免伪共享主要有以下两种方式:
缓存行填充(Padding):为了避免伪共享就需要将可能造成伪共享的多个变量处于不同的缓存行中,可以采用在变量后面填充字节的方式达到该目的。
使用某些语言或编译器中强制变量对齐,将变量都对齐到缓存行大小,避免伪共享发生。
当我们需要判断一个数是否为2的幂时,我们可以将其不断的除以2,直到余数不为0是判断当前被除数是否为1。然而该方法有些繁琐,更简单的方法如下
1
n & ( n - 1 ) == 0 ; 为 0 则是 2 的幂
1
2
3
4
5
6
7
8
inline string shape_string () const {
ostringstream stream ;
for ( int i = 0 ; i < shape_ . size (); ++ i ) {
stream << shape_ [ i ] << " " ;
}
stream << "(" << count_ << ")" ;
return stream . str ();
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <iostream>
#include <cstdlib>
using namespace std ;
int main () {
int * ptr = ( int * ) malloc ( 10 * sizeof ( int ));
for ( size_t i = 0 ; i < 10 ; i ++ ) ptr [ i ] = i ;
cout << "ptr address = " << ptr << endl ;
// int* ptr2 = (int*)realloc(ptr, 5 * sizeof(int));
// cout << "ptr2 address = " << ptr2 << endl;
// for (size_t i = 0; i < 5; i++)
// cout << ptr2[i] << " ";
// cout << endl;
int * ptr3 = ( int * ) realloc ( ptr , 15 * sizeof ( int ));
cout << "ptr3 address = " << ptr3 << endl ;
for ( size_t i = 0 ; i < 15 ; i ++ )
cout << ptr3 [ i ] << " " ;
cout << endl ;
return 0 ;
}
// ptr address = 0x7fffcc63beb0
// ptr2 address = 0x7fffcc63beb0
// 0 1 2 3 4
// ptr address = 0x7ffff2badeb0
// ptr3 address = 0x7ffff2baeef0
// 0 1 2 3 4 5 6 7 8 9 0 0 0 0 0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
/*
* @Brief: file description
* @Author: liudy
* @Email: deyin.liu@nscc-gz.cn
* @Date: 2021-08-04 09:59:04
* @LastEditors: liudy
* @LastEditTime: 2021-08-04 10:03:06
*/
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
void * print_message_function ( void * ptr );
int main () {
pthread_t thread1 , thread2 ;
char * message1 = "Thread 1" ;
char * message2 = "Thread 2" ;
int iret1 , iret2 ;
/* Create independent threads each of which will execute function */
iret1 =
pthread_create ( & thread1 , NULL , print_message_function , ( void * ) message1 );
iret2 =
pthread_create ( & thread2 , NULL , print_message_function , ( void * ) message2 );
/* Wait till threads are complete before main continues. Unless we */
/* wait we run the risk of executing an exit which will terminate */
/* the process and all threads before the threads have completed. */
pthread_join ( thread1 , NULL );
pthread_join ( thread2 , NULL );
printf ( "Thread 1 returns: %d \n " , iret1 );
printf ( "Thread 2 returns: %d \n " , iret2 );
exit ( 0 );
}
void * print_message_function ( void * ptr ) {
char * message ;
message = ( char * ) ptr ;
printf ( "%s \n " , message );
}
linux 上编译使用g++ -pthread
Threads terminate by explicitly calling pthread_exit, by letting the function return, or by a call to the function exit which will terminate the process including any threads.
1
2
3
4
int pthread_create ( pthread_t * thread ,
const pthread_attr_t * attr ,
void * ( * start_routine )( void * ),
void * arg );
Arguments:
thread - returns the thread id. (unsigned long int defined in bits/pthreadtypes.h)
attr - Set to NULL if default thread attributes are used. (else define members of the struct pthread_attr_t defined in bits/pthreadtypes.h) Attributes include:
detached state (joinable? Default: PTHREAD_CREATE_JOINABLE. Other option: PTHREAD_CREATE_DETACHED)
scheduling policy (real-time? PTHREAD_INHERIT_SCHED, PTHREAD_EXPLICIT_SCHED, SCHED_OTHER)
scheduling parameter
inheritsched attribute (Default: PTHREAD_EXPLICIT_SCHED Inherit from parent thread: PTHREAD_INHERIT_SCHED)
scope (Kernel threads: PTHREAD_SCOPE_SYSTEM User threads: PTHREAD_SCOPE_PROCESS Pick one or the other not both.)
guard size
stack address (See unistd.h and bits/posix_opt.h _POSIX_THREAD_ATTR_STACKADDR)
stack size (default minimum PTHREAD_STACK_SIZE set in pthread.h),
void * (*start_routine) - pointer to the function to be threaded. Function has a single argument: pointer to void.
*arg - pointer to argument of function. To pass multiple arguments, send a pointer to a structure.
1
void pthread_exit ( void * retval );
Arguments:
retval - Return value of thread.
This routine kills the thread.
The threads library provides three synchronization mechanisms:
mutexes - Mutual exclusion lock: Block access to variables by other threads. This enforces exclusive access by a thread to a variable or set of variables.
joins - Make a thread wait till others are complete (terminated).
condition variables - data type pthread_cond_t
1
2
3
4
5
6
7
8
9
10
11
/* Note scope of variable and mutex are the same */
pthread_mutex_t mutex1 = PTHREAD_MUTEX_INITIALIZER ;
int counter = 0 ;
/* Function C */
void functionC ()
{
pthread_mutex_lock ( & mutex1 );
counter ++
pthread_mutex_unlock ( & mutex1 );
}
example
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
void * functionC ();
pthread_mutex_t mutex1 = PTHREAD_MUTEX_INITIALIZER ;
int counter = 0 ;
int main ()
{
int rc1 , rc2 ;
pthread_t thread1 , thread2 ;
/* Create independent threads each of which will execute functionC */
if ( ( rc1 = pthread_create ( & thread1 , NULL , & functionC , NULL )) )
{
printf ( "Thread creation failed: %d \n " , rc1 );
}
if ( ( rc2 = pthread_create ( & thread2 , NULL , & functionC , NULL )) )
{
printf ( "Thread creation failed: %d \n " , rc2 );
}
/* Wait till threads are complete before main continues. Unless we */
/* wait we run the risk of executing an exit which will terminate */
/* the process and all threads before the threads have completed. */
pthread_join ( thread1 , NULL );
pthread_join ( thread2 , NULL );
exit ( 0 );
}
void * functionC ()
{
pthread_mutex_lock ( & mutex1 );
counter ++ ;
printf ( "Counter value: %d \n " , counter );
pthread_mutex_unlock ( & mutex1 );
}
A join is performed when one wants to wait for a thread to finish. A thread calling routine may launch multiple threads then wait for them to finish to get the results. One wait for the completion of the threads with a join.
The pthread_join function will block the caller until the thread you specify has terminated.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <stdio.h>
#include <pthread.h>
#define NTHREADS 10
void * thread_function ( void * );
pthread_mutex_t mutex1 = PTHREAD_MUTEX_INITIALIZER ;
int counter = 0 ;
main ()
{
pthread_t thread_id [ NTHREADS ];
int i , j ;
for ( i = 0 ; i < NTHREADS ; i ++ )
{
pthread_create ( & thread_id [ i ], NULL , thread_function , NULL );
}
for ( j = 0 ; j < NTHREADS ; j ++ )
{
pthread_join ( thread_id [ j ], NULL );
}
/* Now that all threads are complete I can print the final result. */
/* Without the join I could be printing a value before all the threads */
/* have been completed. */
printf ( "Final counter value: %d \n " , counter );
}
void * thread_function ( void * dummyPtr )
{
printf ( "Thread number %ld \n " , pthread_self ());
pthread_mutex_lock ( & mutex1 );
counter ++ ;
pthread_mutex_unlock ( & mutex1 );
}
Functions used in conjunction with the condition variable:
Creating/Destroying:
pthread_cond_initpthread_cond_t cond = PTHREAD_COND_INITIALIZER;pthread_cond_destroy
Waiting on condition:pthread_cond_waitpthread_cond_timedwait - place limit on how long it will block.
Waking thread based on condition:pthread_cond_signalpthread_cond_broadcast - wake up all threads blocked by the specified condition variable.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
pthread_mutex_t count_mutex = PTHREAD_MUTEX_INITIALIZER ;
pthread_mutex_t condition_mutex = PTHREAD_MUTEX_INITIALIZER ;
pthread_cond_t condition_cond = PTHREAD_COND_INITIALIZER ;
void * functionCount1 ();
void * functionCount2 ();
int count = 0 ;
#define COUNT_DONE 10
#define COUNT_HALT1 3
#define COUNT_HALT2 6
int main ()
{
pthread_t thread1 , thread2 ;
pthread_create ( & thread1 , NULL , & functionCount1 , NULL );
pthread_create ( & thread2 , NULL , & functionCount2 , NULL );
pthread_join ( thread1 , NULL );
pthread_join ( thread2 , NULL );
exit ( 0 );
}
void * functionCount1 ()
{
for (;;)
{
pthread_mutex_lock ( & condition_mutex );
while ( count >= COUNT_HALT1 && count <= COUNT_HALT2 )
{
pthread_cond_wait ( & condition_cond , & condition_mutex );
}
pthread_mutex_unlock ( & condition_mutex );
pthread_mutex_lock ( & count_mutex );
count ++ ;
printf ( "Counter value functionCount1: %d \n " , count );
pthread_mutex_unlock ( & count_mutex );
if ( count >= COUNT_DONE ) return ( NULL );
}
}
void * functionCount2 ()
{
for (;;)
{
pthread_mutex_lock ( & condition_mutex );
if ( count < COUNT_HALT1 || count > COUNT_HALT2 )
{
pthread_cond_signal ( & condition_cond );
}
pthread_mutex_unlock ( & condition_mutex );
pthread_mutex_lock ( & count_mutex );
count ++ ;
printf ( "Counter value functionCount2: %d \n " , count );
pthread_mutex_unlock ( & count_mutex );
if ( count >= COUNT_DONE ) return ( NULL );
}
}
1
2
template < class F , class ... Args >
/*unspecified*/ bind ( F && f , Args && ... args );
f - Callable object (function object, pointer to function, reference to function, pointer to member function, or pointer to data member) that will be bound to some arguments
args - list of arguments to bind, with the unbound arguments replaced by the placeholders _1, _2, _3... of namespace std::placeholders
用于给函数绑定某些参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <random>
#include <iostream>
#include <memory>
#include <functional>
void f ( int n1 , int n2 , int n3 , const int & n4 , int n5 )
{
std :: cout << n1 << ' ' << n2 << ' ' << n3 << ' ' << n4 << ' ' << n5 << '\n' ;
}
int g ( int n1 )
{
return n1 ;
}
struct Foo {
void print_sum ( int n1 , int n2 )
{
std :: cout << n1 + n2 << '\n' ;
}
int data = 10 ;
};
int main ()
{
using namespace std :: placeholders ; // for _1, _2, _3...
std :: cout << "1) argument reordering and pass-by-reference: " ;
int n = 7 ;
// (_1 and _2 are from std::placeholders, and represent future
// arguments that will be passed to f1)
auto f1 = std :: bind ( f , _2 , 42 , _1 , std :: cref ( n ), n );
n = 10 ;
f1 ( 1 , 2 , 1001 ); // 1 is bound by _1, 2 is bound by _2, 1001 is unused
// makes a call to f(2, 42, 1, n, 7)
return 0 ;
}
Output:
argument reordering and pass-by-reference: 2 42 1 10 7
1
2
template < class R , class ... Args >
class function < R ( Args ...) >
返回一个可调用的函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
#include <functional>
#include <iostream>
struct Foo {
Foo ( int num ) : num_ ( num ) {}
void print_add ( int i ) const { std :: cout << num_ + i << '\n' ; }
int num_ ;
};
void print_num ( int i )
{
std :: cout << i << '\n' ;
}
struct PrintNum {
void operator ()( int i ) const
{
std :: cout << i << '\n' ;
}
};
int main ()
{
// store a free function
std :: function < void ( int ) > f_display = print_num ;
f_display ( - 9 );
// store a lambda
std :: function < void () > f_display_42 = []() { print_num ( 42 ); };
f_display_42 ();
// store the result of a call to std::bind
std :: function < void () > f_display_31337 = std :: bind ( print_num , 31337 );
f_display_31337 ();
// store a call to a member function
std :: function < void ( const Foo & , int ) > f_add_display = & Foo :: print_add ;
const Foo foo ( 314159 );
f_add_display ( foo , 1 );
// store a call to a member function and object
using std :: placeholders :: _1 ;
std :: function < void ( int ) > f_add_display2 = std :: bind ( & Foo :: print_add , foo , _1 );
f_add_display2 ( 2 );
// store a call to a member function and object ptr
std :: function < void ( int ) > f_add_display3 = std :: bind ( & Foo :: print_add , & foo , _1 );
f_add_display3 ( 3 );
// store a call to a function object
std :: function < void ( int ) > f_display_obj = PrintNum ();
f_display_obj ( 18 );
return 0 ;
}
Clang Thread Safety Analysis is a C++ language extension which warns about potential race conditions in code. The analysis is completely static (i.e. compile-time); there is no run-time overhead. It is being developed by Google, in collaboration with CERT/SEI, and is used extensively in Google’s internal code base.
是一种针对于多线程编程的静态分析机制,目的是在编译期编译期就能够通过静态分析避免一些可能会出现数据竞争然而没有加锁的情形
1
2
3
4
5
6
7
bool ( const std :: string & fname ) LOCKS_EXCLUDED ( mu_ ) {
mu_ . Lock ();
bool succeeded = locked_files_ . insert ( fname ). second ;
mu_ . Unlock ();
return succeeded ;
}
GUARDED_BY表示变量被锁保护
EXCLUSIVE_LOCKS_REQUIRED 表示函数被调用的时候,本线程已经占有锁,否则会出错
LOCKS_EXCLUDED 表示函数被调用的时候,本线程没有占有锁,否则会出错
Lambda表达式完整的声明格式如下:
[capture list] (params list) mutable exception-> return type { function body }[capture list] (params list) -> return type {function body} 声明了 const 类型的表达式,这种类型的表达式不能修改捕获列表中的值[capture list] (params list) {function body} 省略了返回值类型,但编译器可以根据以下规则推断出Lambda表达式的返回类型: (1):如果function body中存在return语句,则该Lambda表达式的返回类型由return语句的返回类型确定; (2):如果function body中没有return语句,则返回值为void类型。[capture list] {function body} 省略了参数列表,类似普通函数中的无参函数
capture list:捕获外部变量列表; params list:形参列表; mutable 指示符:用来说用是否可以修改捕获的变量; exception :异常设定; return type:返回类型; function body:函数体
Lambda表达式可以使用其可见范围内的外部变量,但必须明确声明(明确声明哪些外部变量可以被该Lambda表达式使用)。那么,在哪里指定这些外部变量呢?Lambda表达式通过在最前面的方括号[]来明确指明其内部可以访问的外部变量,这一过程也称过Lambda表达式“捕获”了外部变量。
1
2
3
4
5
6
7
8
9
10
11
12
#include <iostream>
using namespace std ;
int main ()
{
int a = 123 ;
auto f = [ a ] { cout << a << endl ; };
f (); // 输出:123
//或通过“函数体”后面的‘()’传入参数
auto x = []( int a ){ cout << a << endl ;}( 123 );
}
Lambda 在C++14可以函数body里引入新的variables,它可以周围的scope中捕获variables,哪些variables能被捕获,以传值或是引用,都需要说明。
Boost.Asio Boost.Asio是一个跨平台的、主要用于网络和其他一些底层输入/输出编程的C++库。实际上asio是一个事件框架,并且 可扩展性很强,比如可扩展模拟actor模型,pipeline模型,支持future, 各种静多态支持,异步串口通信,支持自定义部分调度器功能,有栈/无栈协程支持等
同步VS异步
首先,异步编程和同步编程是非常不同的。在同步编程中,所有的操作都是顺序执行的,比如从socket中读取(请求),然后写入(回应)到socket中。每一个操作都是阻塞的。因为操作是阻塞的,所以为了不影响主程序,当在socket上读写时,通常会创建一个或多个线程来处理socket的输入/输出。因此,同步的服务端/客户端通常是多线程的。
相反的,异步编程是事件驱动的。虽然启动了一个操作,但是你不知道它何时会结束;它只是提供一个回调给你,当操作结束时,它会调用这个API,并返回操作结果。对于有着丰富经验的QT(诺基亚用来创建跨平台图形用户界面应用程序的库)程序员来说,这就是他们的第二天性。因此,在异步编程中,你只需要一个线程。
基础的同步客户端例子:
1
2
3
4
5
using boost :: asio ;
io_service service ;
ip :: tcp :: endpoint ep ( ip :: address :: from_string ( "127.0.0.1" ), 2001 );
ip :: tcp :: socket sock ( service );
sock . connect ( ep );
首先,你的程序至少需要一个io_service实例。Boost.Asio使用io_service同操作系统的输入/输出服务进行交互。通常一个io_service的实例就足够了。然后,创建你想要连接的地址和端口,再建立socket。把socket连接到你创建的地址和端口
简单的使用Boost.Asio的服务端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
typedef boost :: shared_ptr < ip :: tcp :: socket > socket_ptr ;
io_service service ;
ip :: tcp :: endpoint ep ( ip :: tcp :: v4 (), 2001 ); // listen on 2001
ip :: tcp :: acceptor acc ( service , ep );
while ( true ) {
socket_ptr sock ( new ip :: tcp :: socket ( service ));
acc . accept ( * sock );
boost :: thread ( boost :: bind ( client_session , sock ));
}
void client_session ( socket_ptr sock ) {
while ( true ) {
char data [ 512 ];
size_t len = sock -> read_some ( buffer ( data ));
if ( len > 0 )
write ( * sock , buffer ( "ok" , 2 ));
}
}
首先,同样是至少需要一个 io_service 实例。然后你指定你想要监听的端口,再创建一个接收器——一个用来接收客户端连接的对象。 在接下来的循环中,你创建一个虚拟的 socket 来等待客户端的连接。然后当一个连接被建立时,你创建一个线程来处理这个连接。在 client_session 线程中来读取一个客户端的请求,进行解析,然后返回结果
创建一个异步的客户端:
1
2
3
4
5
6
7
8
9
using boost :: asio ;
io_service service ;
ip :: tcp :: endpoint ep ( ip :: address :: from_string ( "127.0.0.1" ), 2001 );
ip :: tcp :: socket sock ( service );
sock . async_connect ( ep , connect_handler );
service . run ();
void connect_handler ( const boost :: system :: error_code & ec ) {
// 如果ec返回成功我们就可以知道连接成功了
}
在程序中你需要创建至少一个io_service实例。你需要指定连接的地址以及创建socket。
当连接完成时(其完成处理程序)你就异步地连接到了指定的地址和端口,也就是说,connect_handler被调用了。
当connect_handler被调用时,检查错误代码(ec),如果成功,你就可以向服务端进行异步的写入。
注意 :只要还有待处理的异步操作,servece.run()循环就会一直运行。在上述例子中,只执行了一个这样的操作,就是socket的async_connect。在这之后,service.run()就退出了。
每一个异步操作都有一个完成处理程序——一个操作完成之后被调用的函数。
一个基本的异步服务端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
using boost :: asio ;
typedef boost :: shared_ptr < ip :: tcp :: socket > socket_ptr ;
io_service service ;
ip :: tcp :: endpoint ep ( ip :: tcp :: v4 (), 2001 )); // 监听端口2001
ip :: tcp :: acceptor acc ( service , ep );
socket_ptr sock ( new ip :: tcp :: socket ( service ));
start_accept ( sock );
service . run ();
void start_accept ( socket_ptr sock ) {
acc . async_accept ( * sock , boost :: bind ( handle_accept , sock , _1 ) );
}
void handle_accept ( socket_ptr sock , const boost :: system :: error_code &
err ) {
if ( err ) return ;
// 从这里开始, 你可以从socket读取或者写入
socket_ptr sock ( new ip :: tcp :: socket ( service ));
start_accept ( sock );
}
在上述代码片段中,首先,你创建一个io_service实例,指定监听的端口。然后,你创建接收器acc——一个接受客户端连接,创建虚拟的socket,异步等待客户端连接的对象。
最后,运行异步service.run()循环。当接收到客户端连接时,handle_accept被调用(调用async_accept的完成处理程序)。如果没有错误,这个socket就可以用来做读写操作。
在使用这个 socket 之后,你创建了一个新的 socket,然后再次调用 start_accept(),用来创建另外一个“等待客户端连接”的异步操作,从而使 service.run() 循环一直保持忙碌状态
当说到Boost.Asio的线程时,我们经常在讨论:
io_service:io_service是线程安全的。几个线程可以同时调用io_service::run()。大多数情况下你可能在一个单线程函数中调用io_service::run(),这个函数必须等待所有异步操作完成之后才能继续执行。然而,事实上你可以在多个线程中调用io_service::run()。这会阻塞所有调用io_service::run()的线程。只要当中任何一个线程调用了io_service::run(),所有的回调都会同时被调用;这也就意味着,当你在一个线程中调用io_service::run()时,所有的回调都被调用了。
socket:socket类不是线程安全的。所以,你要避免在某个线程里读一个socket时,同时在另外一个线程里面对其进行写入操作。(通常来说这种操作都是不推荐的,更别说Boost.Asio)。
utility:就utility来说,因为它不是线程安全的,所以通常也不提倡在多个线程里面同时使用。里面的方法经常只是在很短的时间里面使用一下,然后就释放了。
除了你自己创建的线程,Boost.Asio本身也包含几个线程。但是可以保证的是那些线程不会调用你的代码。这也意味着,只有调用了io_service::run()方法的线程才会调用回调函数。
Boost.Asio支持信号量,比如SIGTERM(软件终止)、SIGINT(中断信号)、SIGSEGV(段错误)等等。 你可以创建一个signal_set实例,指定异步等待的信号量,然后当这些信号量产生时,就会调用你的异步处理程序:
1
2
3
4
5
6
void signal_handler ( const boost :: system :: error_code & err , int signal )
{
// 纪录日志,然后退出应用
}
boost :: asio :: signal_set sig ( service , SIGINT , SIGTERM );
sig . async_wait ( signal_handler );
一些I/O操作需要一个超时时间。这只能应用在异步操作上(同步意味着阻塞,因此没有超时时间)。例如,下一条信息必须在100毫秒内从你的同伴那传递给你。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
bool read = false ;
void deadline_handler ( const boost :: system :: error_code & ) {
std :: cout << ( read ? "read successfully" : "read failed" ) << std :: endl ;
}
void read_handler ( const boost :: system :: error_code & ) {
read = true ;
}
ip :: tcp :: socket sock ( service );
…
read = false ;
char data [ 512 ];
sock . async_read_some ( buffer ( data , 512 ));
deadline_timer t ( service , boost :: posix_time :: milliseconds ( 100 ));
t . async_wait ( & deadline_handler );
service . run ();
io_service是这个库里面最重要的类;它负责和操作系统打交道,等待所有异步操作的结束,然后为每一个异步操作调用其完成处理程序。
一个io_service实例和一个处理线程的单线程例子:我们在一个线程中等待三个操作全部完成,第1个操作一完成,我们就调用它的完成处理程序。尽管操作2紧接着完成了,但是操作2的完成处理程序需要在1秒钟后,也就是操作1的完成处理程序完成时才会被调用。
1
2
3
4
5
6
7
io_service service ; // 所有socket操作都由service来处理
ip :: tcp :: socket sock1 ( service ); // all the socket operations are handled by service
ip :: tcp :: socket sock2 ( service ); sock1 . asyncconnect ( ep , connect_handler );
sock2 . async_connect ( ep , connect_handler );
deadline_timer t ( service , boost :: posixtime :: seconds ( 5 ));
t . async_wait ( timeout_handler );
service . run ();
一个io_service实例和多个处理线程的多线程例子:在两个线程中等待3个异步操作结束。当操作1完成时,我们在第1个线程中调用它的完成处理程序。当操作2完成时,紧接着,我们就在第2个线程中调用它的完成处理程序(当线程1在忙着响应操作1的处理程序时,线程2空闲着并且可以回应任何新进来的操作)。
1
2
3
4
5
6
7
8
9
10
11
12
13
io_service service ;
ip :: tcp :: socket sock1 ( service );
ip :: tcp :: socket sock2 ( service );
sock1 . asyncconnect ( ep , connect_handler );
sock2 . async_connect ( ep , connect_handler );
deadline_timer t ( service , boost :: posixtime :: seconds ( 5 ));
t . async_wait ( timeout_handler );
for ( int i = 0 ; i < 5 ; ++ i )
boost :: thread ( run_service );
void run_service ()
{
service . run ();
}
多个io_service实例和多个处理线程的多线程例子:因为操作1是sock1的connect,操作2是sock2的connect,所以应用程序会表现得像第二个例子一样。线程1会处理sock1 connect操作的完成处理程序,线程2会处理sock2的connect操作的完成处理程序。然而,如果sock1的connect操作是操作1,deadline_timer t的超时操作是操作2,线程1会结束正在处理的sock1 connect操作的完成处理程序。因而,deadline_timer t的超时操作必须等sock1 connect操作的完成处理程序结束(等待1秒钟),因为线程1要处理sock1的连接处理程序和t的超时处理程序。
1
2
3
4
5
6
7
8
9
10
11
12
13
io_service service [ 2 ];
ip :: tcp :: socket sock1 ( service [ 0 ]);
ip :: tcp :: socket sock2 ( service [ 1 ]);
sock1 . asyncconnect ( ep , connect_handler );
sock2 . async_connect ( ep , connect_handler );
deadline_timer t ( service [ 0 ], boost :: posixtime :: seconds ( 5 ));
t . async_wait ( timeout_handler );
for ( int i = 0 ; i < 2 ; ++ i )
boost :: thread ( boost :: bind ( run_service , i ));
void run_service ( int idx )
{
service [ idx ]. run ();
}
异步run(), runone(), poll(), poll one(), 大多数时候使用service.run()就可以。
如果有等待执行的操作,run()会一直执行,直到你手动调用io_service::stop()。为了保证io_service一直执行,通常你添加一个或者多个异步操作,然后在它们被执行时,你继续一直不停地添加异步操作,比如下面代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
using namespace boost :: asio ;
io_service service ;
ip :: tcp :: socket sock ( service );
char buff_read [ 1024 ], buff_write [ 1024 ] = "ok" ;
void on_read ( const boost :: system :: error_code & err , std :: size_t bytes );
void on_write ( const boost :: system :: error_code & err , std :: size_t bytes )
{
sock . async_read_some ( buffer ( buff_read ), on_read );
}
void on_read ( const boost :: system :: error_code & err , std :: size_t bytes )
{
// ... 处理读取操作 ...
sock . async_write_some ( buffer ( buff_write , 3 ), on_write );
}
void on_connect ( const boost :: system :: error_code & err ) {
sock . async_read_some ( buffer ( buff_read ), on_read );
}
int main ( int argc , char * argv []) {
ip :: tcp :: endpoint ep ( ip :: address :: from_string ( "127.0.0.1" ), 2001 );
sock . async_connect ( ep , on_connect );
service . run ();
}
当 service.run() 被调用时,有一个异步操作在等待。
当 socket 连接到服务端时,on_connect 被调用了,它会添加一个异步操作。
当 on_connect 结束时,我们会留下一个等待的操作(read)。
当 on_read 被调用时,我们写入一个回应,这又添加了另外一个等待的操作。
当 on_read 结束时,我们会留下一个等待的操作(write)。
当 on_write 操作被调用时,我们从服务端读取另外一个消息,这也添加了另外一个等待的操作。
当 on_write 结束时,我们有一个等待的操作(read)。
然后一直继续循环下去,直到我们关闭这个应用。
异步工作不仅仅指用异步地方式接受客户端到服务端的连接、异步地从一个socket读取或者写入到socket。它包含了所有可以异步执行的操作。
默认情况下,你是不知道每个异步handler的调用顺序的。除了通常的异步调用(来自异步socket的读取/写入/接收)。你可以使用service.post()来使你的自定义方法被异步地调用。例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
#include <boost/thread.hpp>
#include <boost/bind.hpp>
#include <boost/asio.hpp>
#include <iostream>
using namespace boost :: asio ;
io_service service ;
void func ( int i ) {
std :: cout << "func called, i= " << i << std :: endl ;
}
void worker_thread () {
service . run ();
}
int main ( int argc , char * argv []) {
for ( int i = 0 ; i < 10 ; ++ i )
service . post ( boost :: bind ( func , i ));
boost :: thread_group threads ;
for ( int i = 0 ; i < 3 ; ++ i )
threads . create_thread ( worker_thread );
// 等待所有线程被创建完
boost :: this_thread :: sleep ( boost :: posix_time :: millisec ( 500 ));
threads . join_all ();
}
在linux系统中创建进程有两种方式:一是由操作系统创建,二是由父进程创建进程(通常为子进程)。系统调用函数fork()是创建一个新进程的唯一方式,fork()函数是Linux系统中一个比较特殊的函数,其一次调用会有两个返回值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#include <unistd.h>
#include <stdio.h>
int main ()
{
pid_t fpid ;
fpid = fork ();
if ( fpid < 0 ) {
printf ( "error in fork!" );
} else if ( fpid == 0 ) {
printf ( "this is child process, pid %d/n" , getpid ());
} else {
printf ( "this is parent process, pid %d/n" , getpid ());
}
return 0 ;
}
fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
在父进程中,fork返回新创建子进程的进程ID;
在子进程中,fork返回0;
如果出现错误,fork返回一个负值;
在fork函数执行完毕后,如果创建新进程成功,则出现两个进程,一个是子进程,一个是父进程。在子进程中,fork函数返回0,在父进程中,fork返回新创建子进程的进程ID。
函数原型
1
2
3
4
5
6
7
8
9
#include <unistd.h>
extern char ** environ ;
int execl ( const char * path , const char * arg , ...);
int execlp ( const char * file , const char * arg , ...);
int execv ( const char * path , char * const argv []);
int execvp ( const char * file , char * const argv []);
int execle ( const char * path , const char * arg ,..., char * const envp []);
int execvpe ( const char * file , char * const argv [], char * const envp []);
参数说明:
path:可执行文件的路径名字
arg: 可执行程序所带的参数,第一个参数为可执行文件名字,没有带路径且arg必须以NULL结束
file:如果参数file中包含 / ,则就将其视为路径名,否则就按PATH环境变量,在它所指定的各目录中搜寻可执行文件
返回值:exec函数族的函数执行成功后不会返回,调用失败时,会设置errno(调用perror函数可以知道发生错误的原因)并返回-1,然后从原程序的调用点接着往下执行
exec族函数参数极难记忆和分辨,函数名中的字符会给我们一些帮助:
l : 使用参数列表
p:使用文件名,并从PATH环境进行寻找可执行文件
v:应先构造一个指向各参数的指针数组,然后将该数组的地址作为这些函数的参数。
e:多了envp[]数组,使用新的环境变量代替调用进程的环境变量
基本用法
1
2
3
4
5
6
#define PI 3.1415926
#define S(a, b) a*b
// 更好的做法,给宏体中的每个参数加上括号,并在整个宏体上再加一个括号。
#define area(x) ((x)*(x))
由于C++增加了内置函数(inline),比用带参数的宏定义更方便,因此在C++中基本上已不再用#define命令定义宏了,主要用于条件编译中。
带参宏定义中,宏名和形参表之间不能有空格出现: #define Max (a,b) (a>b?a:b.
define中的三个特殊符号:#,##,#@
#define Conn(x,y) x##y, 表示 x 连接 y
1
int n = Conn ( 23 , 456 ) // 即 n = 123456
#define ToChar(x) #@x , 给 x 加上单引号,结果返回一个 const char
1
char a = ToChar ( 1 ); // a = '1'
#define ToString(x) #x , 给 x 加上一个双引号
1
char * str = ToString ( 123321 ); // str = "123321"
1
2
3
4
5
6
7
8
9
10
11
12
13
#include "python3.8/Python.h"
#include <iostream>
using namespace std ;
int main ()
{
Py_Initialize ();
PyRun_SimpleString ( "print('hello')" );
Py_Finalize ();
return 0 ;
}
compile with
g++ python_pthread.cpp -I/usr/include/python3.8 -lpython3.8
如果在程序中定义了一个函数,那么在编译时系统就会为这个函数代码分配一段存储空间,这段存储空间的首地址称为这个函数的地址。而且函数名表示的就是这个地址。既然是地址我们就可以定义一个指针变量来存放,这个指针变量就叫作函数指针变量,简称函数指针。
函数指针的定义方式为:
函数返回值类型 (* 指针变量名) (函数参数列表);
1
2
3
int Func ( int x ); /*声明一个函数*/
int ( * p ) ( int x ); /*定义一个函数指针*/
p = Func ; /*将Func函数的首地址赋给指针变量p*/
用户空间和内核空间:
对于32位操作系统而言,它的寻址空间是4G(2的32次方),注意这里的4G是虚拟内存空间大小。以 Linux 为例,它将最高的1G字节给内核使用,称为内核空间,剩下的3G给用户进程使用,称为用户空间。这样做的好处就是隔离,保证内核安全。
文件描述符:
在 Linux 世界里,一切皆文件。怎么理解呢?当程序打开一个现有文件或创建新文件时,内核会向进程返回一个文件描述符,文件描述符在形式上是一个非负整数,其实就是一个索引值,指向该进程打开文件的记录表(它是由内核维护的)。
缓存 I/O
和标准 IO 是一个概念,当应用程序需要从内核读数据时,数据先被拷贝到操作系统的内核缓冲区(page cache),然后再从该缓冲区拷贝到应用程序的地址空间。
Linux IO 模式:
当应用程序发起一次 read 调用时,会经历以下两个阶段:
等待数据准备 (Waiting for the data to be ready)
将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
IO 多路复用
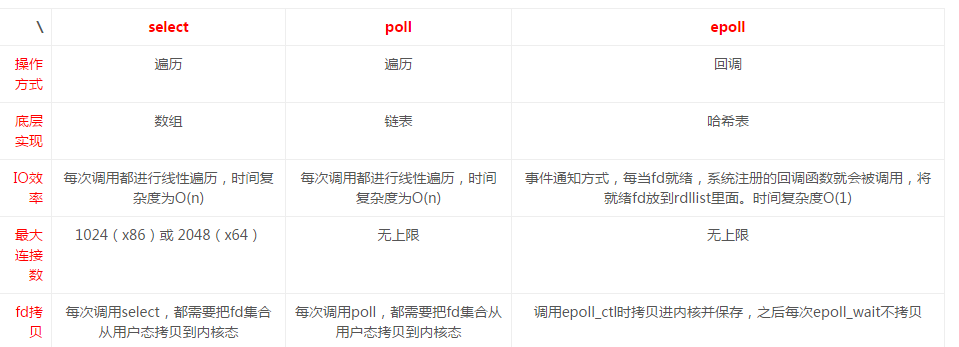
I/O 多路复用的特点是通过一种机制一个进程能同时等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,select()函数就可以返回。
select,poll,epoll 都是 IO 多路复用的机制,它们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的。
epoll 有两种工作方式:
LT模式(水平触发):若就绪的事件一次没有处理完,就会一直去处理。也就是说,将没有处理完的事件继续放回到就绪队列之中(即那个内核中的链表),一直进行处理。
ET模式(边缘触发):就绪的事件只能处理一次,若没有处理完会在下次的其它事件就绪时再进行处理。而若以后再也没有就绪的事件,那么剩余的那部分数据也会随之而丢失。
由此可见:ET模式的效率比LT模式的效率要高很多。简单点说就是,如果对于一个非阻塞 socket,如果使用 epoll 边缘模式去检测数据是否可读,触发可读事件以后,一定要一次性把 socket 上的数据收取干净才行,也就是说一定要循环调用 recv 函数直到 recv 出错,错误码是EWOULDBLOCK(EAGAIN 一样)(此时表示 socket 上本次数据已经读完);如果使用水平模式,则不用,你可以根据业务一次性收取固定的字节数,或者收完为止。只是如果使用ET模式,就要保证每次进行数据处理时,要将其处理完,不能造成数据丢失,这样对编写代码的人要求就比较高。
You have a header file that references classes in other headers, and you need to
reduce compilation dependencies.
1
2
3
4
5
6
7
8
9
10
11
12
// myheader.h
#ifndef MYHEADER_H_ _
#define MYHEADER_H_ _
class A ; // No need to include A's header
class B {
public :
void f ( const A & a );
// ...
private :
A * a_ ;
};
#endif
However, if you include any definition in myheader.h that uses members of A,
you have to #include A’s header.
C++性能榨汁机之伪共享 pthread tutorial Thread Posix Condition Variables Condition Variables Boost.Asio C++ 网络编成 boost Asio documentation Python/C API Reference Manual