#include<iostream>usingnamespacestd;classA{public:A(){array=newint[5];}// A(const A& a) {
// array = new int [5];
// }
A(const)~A(){cout<<"Destory"<<endl;delete[]array;}private:int*array;};voidfunc(Aa){return;}intmain(){Aa;func(a);// this will occur double free error! Need add Copy construcot
return0;}
#include<iostream>#include<vector>usingnamespacestd;classA{public:A(){arr=newint[2];arr[0]=5;arr[1]=8;}~A(){cout<<count<<" time Destroy A!"<<endl;count++;}voidshow(){cout<<arr[0]<<" "<<arr[1]<<endl;}private:int*arr;staticintcount;};intA::count=1;intmain(){vector<A*>v;for(inti=0;i<4;i++){Atmp;v.push_back(tmp);}v[0].show();return0;}=>1timeDestroyA!2timeDestroyA!3timeDestroyA!4timeDestroyA!5timeDestroyA!6timeDestroyA!7timeDestroyA!588timeDestroyA!9timeDestroyA!10timeDestroyA!11timeDestroyA!
此处采用继承的原因,在后面进行论述。
```c++
// 重载
template <class InputIterator, class Distance>
void __advance(InputItertor& i, Distance n, input_iterator_tag) {
while (n--) ++i;
}
template <class ForwardIterator, class Distance>
void __advance(ForwardIterator& i, Distance n, forward_itertor_tag) {
advance(i, n, input_iterator_tag());
}
tempalte <class BidiectionalItertor, class Distance>
void __advance(BidiectionalIterator& i, Distance n, bidirectional_iterator_tag) {
if (n >= 0)
while (n--) ++i;
else
while (n++) --i;
}
tempalte <class RandomAccessIterator, class Distance>
void __advance(RandomAccessIterator& i, Distance n, random_access_iterator_tag) {
i += n;
}
#include<iostream>usingnamespacestd;structB{};structD1:publicB{};structD2:publicD1{};template<classI>func(I&p,B){cout<<"B version"<<endl;}template<classI>func(I&p,D2){cout<<"D2 version"<<endl;}intmain(){int*p;func(p,B());// output: B version
func(p,D1());// output: B version
func(p,D2());// output: D2 version
}
#include<iostream>#include<vector>usingnamespacestd;intmain(){vector<unsignedint>myvector;unsignedintcapacity=myvector.capacity();for(unsignedinti=0;i<100;++i){myvector.push_back(i);if(capacity!=myvector.capacity()){capacity=myvector.capacity();cout<<myvector.capacity()<<endl;cout<<"address of myvector: "<<&(myvector[0])<<endl;}}return0;}
#include<iostream>#include<vector>#include<chrono>usingnamespacestd;usingnamespacestd::chrono;voidfunc1(){autostart=high_resolution_clock::now();vector<int>v;for(inti=0;i<100000000;i++){v.push_back(i);}autoend=high_resolution_clock::now();autoduration=duration_cast<microseconds>(end-start);cout<<"func1 time cost: "<<duration.count()<<" us"<<endl;}voidfunc2(){autostart=high_resolution_clock::now();vector<int>v;v.reserve(100000000);for(inti=0;i<100000000;i++){v.push_back(i);}autoend=high_resolution_clock::now();autoduration=duration_cast<microseconds>(end-start);cout<<"func2 time cost: "<<duration.count()<<" us"<<endl;}intmain(){func1();func2();return0;}=====>func1timecost:1397472msfunc2timecost:1154251ms
set
在 STL 里面 insert 操作,返回值是一个序对 pair , 其中 first 是一个迭代器, second 用于表示插入操作是否发生,如果插入元素已经存在,返回 false, 反之返回 true。
所以我们可以利用该性质进行查重操作。
创建池
#include <iostream>
#include <string>
#include <chrono>
using std::chrono::system_clock;
using namespace std;
#define size 1000000
class A{
public:
A *pre, *next;
static size_t cnt;
A() {
pre = nullptr;
next = nullptr;
}
~A() {
cnt++;
}
};
size_t A::cnt = 0;
int main() {
{
A *list = nullptr, *cur = nullptr;
system_clock::time_point start = system_clock::now();
for (size_t i = 0; i < size; i++) {
A* tem = new A();
if (list == nullptr) {
list = tem;
cur = list;
} else {
cur->next = tem;
tem->pre = cur;
cur = tem;
}
}
system_clock::time_point end = system_clock::now();
std::chrono::duration<double> elapsed_seconds = end - start;
std::cout << "time = " << elapsed_seconds.count() << "s" << std::endl;
start = system_clock::now();
A* array = new A[size];
list = &array[0];
cur = list;
for (size_t i = 1; i < size; i++) {
cur->next = &array[i];
array[i].pre = cur;
cur = cur->next;
}
end = system_clock::now();
elapsed_seconds = end - start;
std::cout << "time = " << elapsed_seconds.count() << "s" << std::endl;
delete[] array;
}
cout << "Call destroy A times: " << A::cnt << endl;
return 0;
}
#include<iostream>#include<cstdio>#define SIZE 1024
usingnamespacestd;intmain(){charbuffer[SIZE]="...";charstr[]="This is first line\nThis is second line";FILE*fp=fopen("test.txt","wb+");/* no buffering, buffer remains unchanged */setvbuf(fp,buffer,_IONBF,SIZE);fwrite(str,sizeof(str),1,fp);cout<<buffer<<endl;/* line buffering, only a single line is buffered */setvbuf(fp,buffer,_IOLBF,SIZE);fwrite(str,sizeof(str),1,fp);cout<<buffer<<endl;/* full buffering, all the contents are buffered */setvbuf(fp,buffer,_IOFBF,SIZE);fwrite(str,sizeof(str),1,fp);cout<<buffer<<endl;fclose(fp);return0;}
Output
...
This is second line
This is first line
This is second line
编程技巧
判断两个浮点数 a 和 b 是否相等时,不要用 a == b , 应该使用 fabs(a - b) < 1e-9
判断一个整数是否为奇数,使用 x % 2 != 0, 不要使用 x % 2 == 1 , 因为 x 可能为负数。若已知 n > 0 可使用 n & 0x1 判断奇偶。
The char buf[] is a placeholder for a string. Since the max length of the string is not known at compiletime, the struct reserves the name for it, so it can be properly adressed.
When memory is allocated at runtime, the allocation must include the length of the string plus the sizeof the struct, and then can pass around the structure with the string, accessible via the array.
宏
1
2
3
4
5
6
7
8
9
#define SAFE_FREE(p) do{free(p); p=NULL;} while(0);
#define CHECK(COND) \
do { \
if (!(COND)) { \
LOG_ERR("Check failure: %s", #COND); \
exit(-1); \
} \
} while (0);
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ..., char * const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
path: 參數表示你要啟動程序的名稱包括路徑名
arg: 參數表示啟動程序所帶的參數,一般第一個參數為要執行命令名,不是帶路徑且 arg 必須以 NULL 結束
返回值:成功返回0,失敗返回-1
1. ,带 l 的 `exec` 函数: `execl,execlp,execle` ,表示后边的参数以可变参数的形式给出且都以一个空指针结束。
```c++
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void)
{
printf("entering main process---\n");
execl("/bin/ls","ls","-l",NULL);
printf("exiting main process ----\n");
return 0;
}
带 p 的 exec函数: execlp,execvp,表示第一个参数 path 不用输入完整路径,只有给出命令名即可,它会在环境变量 PATH 当中查找命令
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#include<stdio.h>#include<stdlib.h>#include<unistd.h>intmain(void){printf("entering main process---\n");intret;char*argv[]={"ls","-l",NULL};ret=execvp("ls",argv);if(ret==-1)perror("execl error");printf("exiting main process ----\n");return0;}
开启进程执行 python 文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
pid_tpid;pid=vfork();if(pid==0){// child process
std::stringhome_path=getenv("HOME");std::stringpath=home_path+"/.rtai/python/rtai/executor/executor.py";strcpy(executor_path,path.c_str());std::stringport=std::to_string(executor_port_);strcpy(port_arg,port.c_str());intret;charcommand[]="python";char*argv[]={command,executor_path,(char*)"--port",port_arg,NULL};ret=execvp("python",argv);if(ret==-1){cout<<"Create python process failed!"<<endl;}}elseif(pid>0){cout<<"Parent process "<<endl;}
#include<iostream>#include<algorithm>#include<cassert>usingnamespacestd;intmain(){vector<int>a={1,3,3,4,5,6,6,7};vector<int>::iteratorit_1=a.begin();vector<int>::iteratorit_2=a.end();vector<int>::iteratornew_end;new_end=unique(it_1,it_2);//注意unique的返回值
a.erase(new_end,it_2);cout<<"删除重复元素后的 a : ";for(inti=0;i<a.size();i++)cout<<a[i];cout<<endl;}
You can create an explicit namespace but not give it a name:
1
2
3
4
namespace{intMyFunc(){}}
This is called an unnamed or anonymous namespace and it is useful when you want to make variable declarations invisible to code in other files (i.e. give them internal linkage) without having to create a named namespace. All code in the same file can see the identifiers in an unnamed namespace but the identifiers, along with the namespace itself, are not visible outside that file—or more precisely outside the translation unit.
This is used in implementation file (cpp/c file).
编译
c++ 头文件默认搜索的库路径 CPLUS_INCLUDE_PATH#include “headfile.h” 的搜索顺序为:
先搜索当前目录
然后搜索 -I 指定的目录
再搜索 gcc 的环境变量 CPLUS_INCLUDE_PATH ( C 程序使用的是 C_INCLUDE_PATH )
#include<stdio.h>#include<sys/types.h>#include<ifaddrs.h>#include<netinet/in.h>#include<string.h>#include<arpa/inet.h>intmain(intargc,constchar*argv[]){structifaddrs*ifAddrStruct=NULL;structifaddrs*ifa=NULL;void*tmpAddrPtr=NULL;getifaddrs(&ifAddrStruct);for(ifa=ifAddrStruct;ifa!=NULL;ifa=ifa->ifa_next){if(!ifa->ifa_addr){continue;}if(ifa->ifa_addr->sa_family==AF_INET){// check it is IP4
// is a valid IP4 Address
tmpAddrPtr=&((structsockaddr_in*)ifa->ifa_addr)->sin_addr;charaddressBuffer[INET_ADDRSTRLEN];inet_ntop(AF_INET,tmpAddrPtr,addressBuffer,INET_ADDRSTRLEN);printf("%s IP4 Address %s\n",ifa->ifa_name,addressBuffer);}elseif(ifa->ifa_addr->sa_family==AF_INET6){// check it is IP6
// is a valid IP6 Address
tmpAddrPtr=&((structsockaddr_in6*)ifa->ifa_addr)->sin6_addr;charaddressBuffer[INET6_ADDRSTRLEN];inet_ntop(AF_INET6,tmpAddrPtr,addressBuffer,INET6_ADDRSTRLEN);printf("%s IP6 Address %s\n",ifa->ifa_name,addressBuffer);}}if(ifAddrStruct!=NULL)freeifaddrs(ifAddrStruct);return0;}
voidparallel_memcopy(uint8_t*dst,constuint8_t*src,int64_tnbytes,uintptr_tblock_size,intnum_threads){std::vector<std::thread>threadpool(num_threads);uint8_t*left=pointer_logical_and(src+block_size-1,~(block_size-1));uint8_t*right=pointer_logical_and(src+nbytes,~(block_size-1));int64_tnum_blocks=(right-left)/block_size;// Update right address
right=right-(num_blocks%num_threads)*block_size;// Now we divide these blocks between available threads. The remainder is
// handled on the main thread.
int64_tchunk_size=(right-left)/num_threads;int64_tprefix=left-src;int64_tsuffix=src+nbytes-right;// Now the data layout is | prefix | k * num_threads * block_size | suffix |.
// We have chunk_size = k * block_size, therefore the data layout is
// | prefix | num_threads * chunk_size | suffix |.
// Each thread gets a "chunk" of k blocks.
// Start all threads first and handle leftovers while threads run.
for(inti=0;i<num_threads;i++){threadpool[i]=std::thread(std::memcpy,dst+prefix+i*chunk_size,left+i*chunk_size,chunk_size);}std::memcpy(dst,src,prefix);std::memcpy(dst+prefix+num_threads*chunk_size,right,suffix);for(auto&t:threadpool){if(t.joinable()){t.join();}}}
/**
* Write a sequence of bytes into a file descriptor. This will block until one
* of the following happens: (1) there is an error (2) end of file, or (3) all
* length bytes have been written.
*
* @param fd The file descriptor to write to. It can be non-blocking.
* @param cursor The cursor pointing to the beginning of the bytes to send.
* @param length The size of the bytes sequence to write.
* @return int Whether there was an error while writing. 0 corresponds to
* success and -1 corresponds to an error (errno will be set).
*/intwrite_bytes(intfd,uint8_t*cursor,size_tlength){ssize_tnbytes=0;while(length>0){/* While we haven't written the whole message, write to the file
* descriptor, advance the cursor, and decrease the amount left to write. */nbytes=write(fd,cursor,length);if(nbytes<0){if(errno==EAGAIN||errno==EWOULDBLOCK){continue;}/* TODO(swang): Return the error instead of exiting. *//* Force an exit if there was any other type of error. */CHECK(nbytes<0);}if(nbytes==0){return-1;}cursor+=nbytes;length-=nbytes;}return0;}
std::thread
class job
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#include<iostream>#include<thread>#include<vector>usingnamespacestd;classWork{public:Work(){}voidoperator()(){cout<<"worker is done"<<endl;}};intmain(intargc,char*argv[]){vector<thread>m_thread(10);m_thread[0]=thread(Work());m_thread[0].join();return0;}
#include<iostream>#include<string>#include<thread>#include<mutex>#include<condition_variable>#include<unistd.h>std::mutexm;std::condition_variablecv;std::stringdata;boolready=false;boolprocessed=false;voidworker_thread(){// Wait until main() sends data
std::unique_lock<std::mutex>lk(m);cv.wait(lk,[]{returnready;});// after the wait, we own the lock.
std::cout<<"Worker thread is processing data\n";data+=" after processing";// Send data back to main()
processed=true;std::cout<<"Worker thread signals data processing completed\n";// Manual unlocking is done before notifying, to avoid waking up
// the waiting thread only to block again (see notify_one for details)
lk.unlock();cv.notify_one();}intmain(){std::threadworker(worker_thread);data="Example data";// send data to the worker thread
{std::lock_guard<std::mutex>lk(m);ready=true;std::cout<<"main() signals data ready for processing\n";}cv.notify_one();// wait for the worker
{std::unique_lock<std::mutex>lk(m);cv.wait(lk,[]{returnprocessed;});}std::cout<<"Back in main(), data = "<<data<<'\n';worker.join();}
Wait until notified
The execution of the current thread (which shall have locked lck's mutex) is blocked until notified.
At the moment of blocking the thread, the function automatically calls lck.unlock(), allowing other locked threads to continue.
Once notified (explicitly, by some other thread), the function unblocks and calls lck.lock(), leaving lck in the same state as when the function was called. Then the function returns (notice that this last mutex locking may block again the thread before returning).
Generally, the function is notified to wake up by a call in another thread either to member notify_one or to member notify_all. But certain implementations may produce spurious wake-up calls without any of these functions being called. Therefore, users of this function shall ensure their condition for resumption is met.
If pred is specified (2), the function only blocks if pred returns false, and notifications can only unblock the thread when it becomes true (which is specially useful to check against spurious wake-up calls). This version (2) behaves as if implemented as:
#include<iostream>#include<string>#include<thread>#include<mutex>#include<condition_variable>#include<unistd.h>std::mutexm;std::condition_variablecv;voidworker_thread(inti){std::unique_lock<std::mutex>lk(m);cv.wait(lk);// after the wait, we own the lock.
std::cout<<i<<" Worker thread is processing data\n";}intmain(){std::threadworker0(worker_thread,0);std::threadworker1(worker_thread,1);std::threadworker2(worker_thread,2);sleep(3);cv.notify_one();std::cout<<"notify one done!"<<std::endl;cv.notify_one();std::cout<<"notify one done!"<<std::endl;cv.notify_one();std::cout<<"notify one done!"<<std::endl;worker0.join();worker1.join();worker2.join();}
#include<iostream>#include<utility>#include<thread>#include<chrono>voidf1(intn){for(inti=0;i<5;++i){std::cout<<"Thread 1 executing\n";++n;std::this_thread::sleep_for(std::chrono::milliseconds(10));}}voidf2(int&n){for(inti=0;i<5;++i){std::cout<<"Thread 2 executing\n";++n;std::this_thread::sleep_for(std::chrono::milliseconds(10));}}classfoo{public:voidbar(){for(inti=0;i<5;++i){std::cout<<"Thread 3 executing\n";++n;std::this_thread::sleep_for(std::chrono::milliseconds(10));}}intn=0;};classbaz{public:voidoperator()(){for(inti=0;i<5;++i){std::cout<<"Thread 4 executing\n";++n;std::this_thread::sleep_for(std::chrono::milliseconds(10));}}intn=0;};intmain(){intn=0;foof;bazb;std::threadt1;// t1 is not a thread
std::threadt2(f1,n+1);// pass by value
std::threadt3(f2,std::ref(n));// pass by reference
std::threadt4(std::move(t3));// t4 is now running f2(). t3 is no longer a thread
std::threadt5(&foo::bar,&f);// t5 runs foo::bar() on object f
std::threadt6(b);// t6 runs baz::operator() on a copy of object b
t2.join();t4.join();t5.join();t6.join();std::cout<<"Final value of n is "<<n<<'\n';std::cout<<"Final value of f.n (foo::n) is "<<f.n<<'\n';std::cout<<"Final value of b.n (baz::n) is "<<b.n<<'\n';}
The arguments to the thread function are moved or copied by value. If a reference argument needs to be passed to the thread function, it has to be wrapped (e.g., with std::ref or std::cref).
Any return value from the function is ignored. If the function throws an exception, std::terminate is called. In order to pass return values or exceptions back to the calling thread, std::promise or std::async may be used.
The function dlopen() loads the dynamic library file named by the null-terminated string filename and returns an opaque "handle" for the dynamic library. If filename is NULL, then the returned handle is for the main program. If filename contains a slash ("/"), then it is interpreted as a (relative or absolute) pathname. Otherwise, the dynamic linker searches for the library
dlsym()
The function dlsym() takes a "handle" of a dynamic library returned by dlopen() and the null-terminated symbol name, returning the address where that symbol is loaded into memory. If the symbol is not found, in the specified library or any of the libraries that were automatically loaded by dlopen() when that library was loaded, dlsym() returns NULL.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#include<stdio.h>#include<stdlib.h>#include<dlfcn.h>typedefint(*Rand)(void);intrand(){printf("in my rand");void*handle=dlopen("libc.so.6",RTLD_LAZY);if(handle==NULL){exit(0);}return((Rand)dlsym(handle,"rand"))();}
structmsghdr{void*msg_name;/* optional address */socklen_tmsg_namelen;/* size of address */structiovec*msg_iov;/* scatter/gather array */size_tmsg_iovlen;/* # elements in msg_iov */void*msg_control;/* ancillary data, see below */size_tmsg_controllen;/* ancillary data buffer len */intmsg_flags;/* flags on received message */};
errno
在 linux 中使用 c 语言编程时,errno可以把最后一次调用 c 的方法的错误代码保留
但是如果最后一次成功的调用 c 的方法, errno 不会改变。因此,只有在 c 语言函数返回值异常时,再检测 errno。 errno 会返回一个数字,每个数字代表一个错误类型。详细的可以查看头文件。 /usr/include/asm/errno.h
将错误代码转换为字符串错误信息
fprintf(stderr,"error in CreateProcess %s, Process ID %d ",strerror(errno),processID)
使用perror函数
void perror(const char *s)
perror() 用来将上一个函数发生错误的原因输出到标准错误(stderr),参数 s 所指的字符串会先打印出,后面再加上错误原因字符串。
#include<stdio.h>#include<unistd.h>intmain(){inttmp=5;pid_tres=fork();if(res<0){//fork失败
perror("fork");}elseif(res==0){//该进程为子进程
printf("im child[%d],fasther is %d,tmp is %d.\n",getpid(),getppid(),tmp++);}else{//该进程为父进程
printf("im father[%d],tmp is %d.\n",getpid(),tmp++);}printf("tmp = %d\n",tmp);return0;}
#include<stdio.h>#include<unistd.h>inttmp=3;intmain(){pid_tres=vfork();if(res<0){perror("vfork");_exit();}elseif(res==0){tmp=10;printf("child res = %d\n",tmp);_exit(0);}else{printf("father res = %d\n",tmp);}return0;}
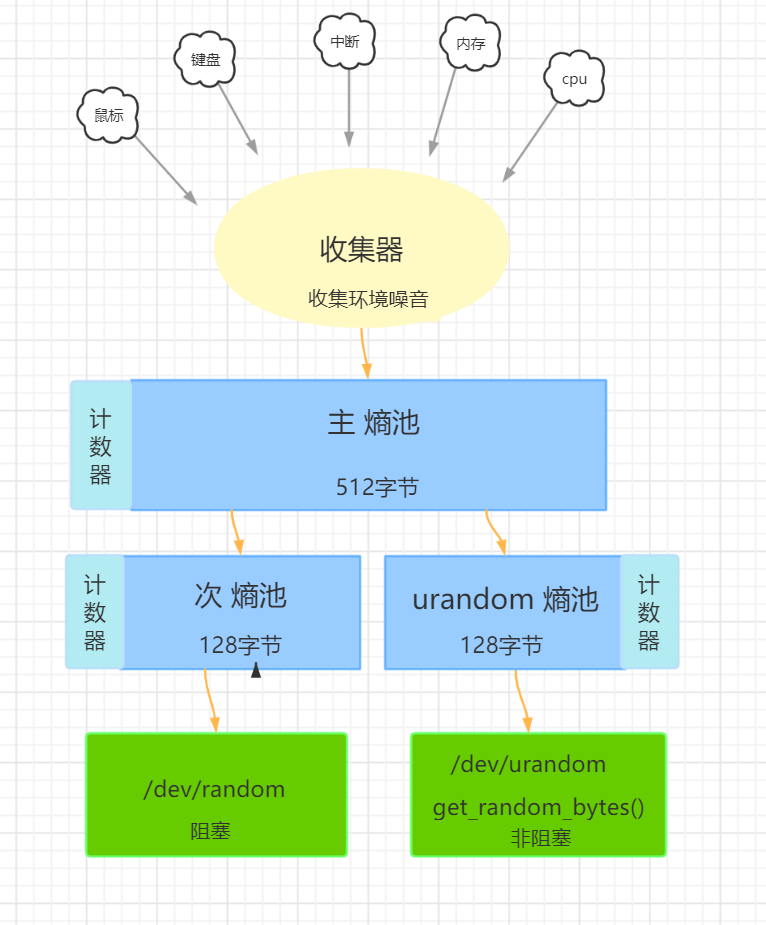 次熵池: /dev/random 设备关连的,大小为128字节,它是阻塞的
次熵池: /dev/random 设备关连的,大小为128字节,它是阻塞的