Basic
一个warp包含32个threads。 warp是调度和执行的基本单位,half-warp是存储器操作的基本单位
|
|
The cudaDeviceSyncronize function determines that all the processing on the GPU must be done before continuing.
- The
__global__keyword indicates that the following function will run on the GPU. - The code executed on the CPU is referred to as host code, and code executed on the GPU is referred to as device code.
- It is required that functions defined with the
__global__keyword return type void. - When calling a function to run on the GPU, we call this function a kernel (In the example, printHelloGPU is the kernel).
- When launching a kernel, we must provide an execution configuration, which is done by using the
<<< ... >>>syntax.
|
|
When some of the threads need to execute an instruction while others don’t, this situation is known as thread divergence. Under normal circumstances, divergent branches simply result in some threads remaining idle, while the other threads actually execute the instructions in the branch.
The Execution Configuration
the execution configuration allows programmers to specify the thread hierarchy for a kernel launch, which defines the number of thread blocks, as well as how many threads to execute in each block.
|
|
A kernel is executed once for every thread in every thread block configured when the kernel is launched.
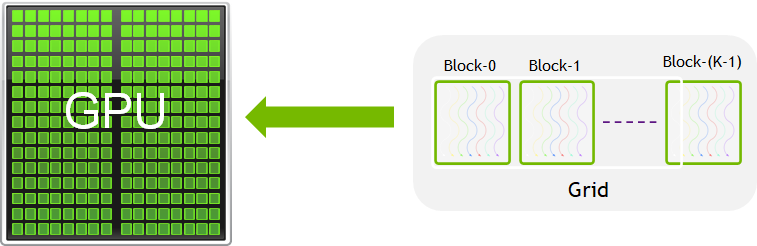 A group of threads is called a CUDA block. CUDA blocks are grouped into a grid. A kernel is executed as a grid of blocks of threads.
A group of threads is called a CUDA block. CUDA blocks are grouped into a grid. A kernel is executed as a grid of blocks of threads.
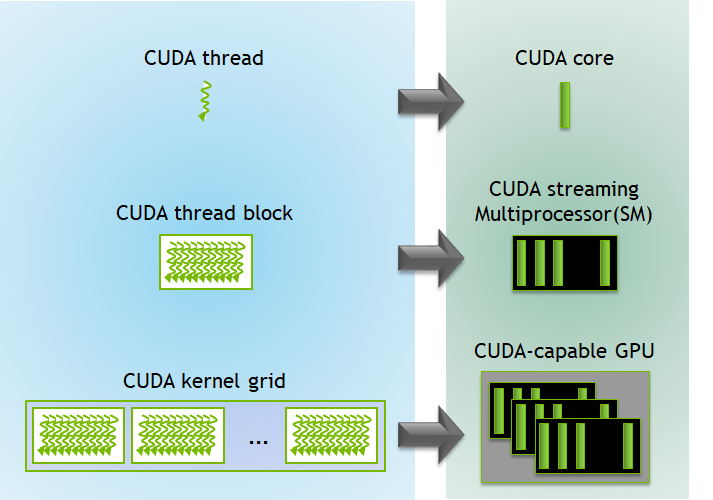 Each CUDA block is executed by one streaming multiprocessor (SM) and cannot be migrated to other SMs in GPU (except during preemption, debugging, or CUDA dynamic parallelism). One SM can run several concurrent CUDA blocks depending on the resources needed by CUDA blocks. Each kernel is executed on one device and CUDA supports running multiple kernels on a device at one time.The above picture shows the kernel execution and mapping on hardware resources available in GPU.
Each CUDA block is executed by one streaming multiprocessor (SM) and cannot be migrated to other SMs in GPU (except during preemption, debugging, or CUDA dynamic parallelism). One SM can run several concurrent CUDA blocks depending on the resources needed by CUDA blocks. Each kernel is executed on one device and CUDA supports running multiple kernels on a device at one time.The above picture shows the kernel execution and mapping on hardware resources available in GPU.
Thread Hierarchy Variables
gridDim.x is the number of the blocks in the grids.
blockIdx.x is the index of the current block within the grid.
blockDim.x is the number of threads in the block. All blocks in a grid contain the same number of threads.
threadIdx.x is index of the thread within a block (starting at 0).
The CUDA threads hierarchy can be 3-dimensional.
|
|
We can use the dim3 structure to specify dimensions for blocks and threads.
Example:
printHelloGPU<<<1, 25>>>()is configured to run in a single thread block which has 25 threads and will, therefore, run 25 times.printHelloGPU<<<1, dim3(5, 5)>>>()is configured to run in a single thread block which has 25 threads and will, therefore, run 25 times.printHelloGPU<<<5, 5>>>()is configured to run in 5 thread blocks which each has 5 threads and will therefore run 25 times.
|
|
|
|
Memory Hierarchy
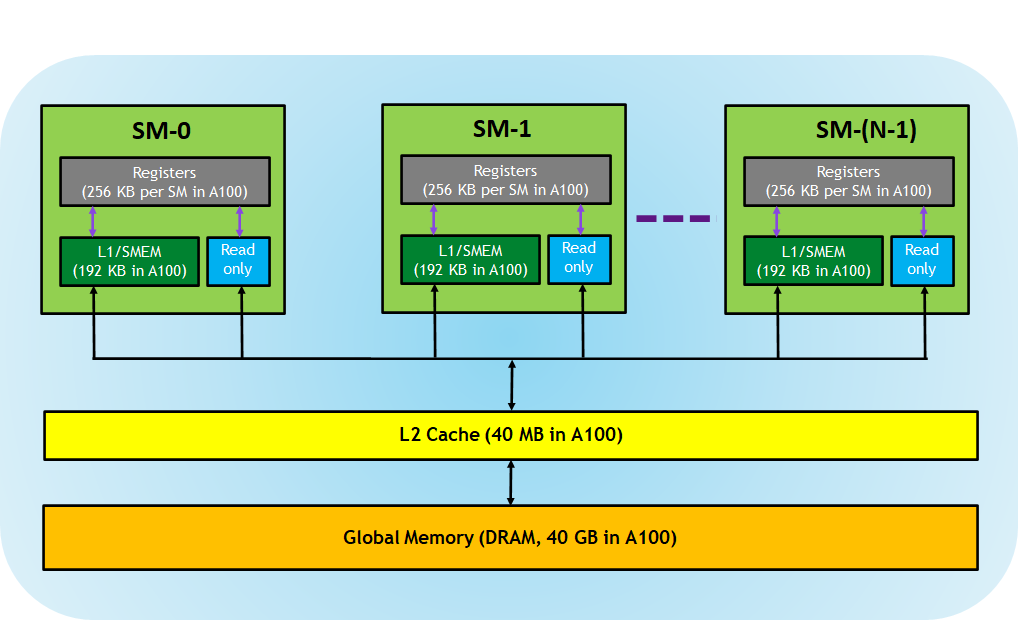
- Registers—These are private to each thread, which means that registers assigned to a thread are not visible to other threads. The compiler makes decisions about register utilization.
- L1/Shared memory (SMEM)—Every SM has a fast, on-chip scratchpad memory that can be used as L1 cache and shared memory. All threads in a CUDA block can share shared memory, and all CUDA blocks running on a given SM can share the physical memory resource provided by the SM..
- Read-only memory—Each SM has an instruction cache, constant memory, texture memory and RO cache, which is read-only to kernel code.
- L2 cache—The L2 cache is shared across all SMs, so every thread in every CUDA block can access this memory. The NVIDIA A100 GPU has increased the L2 cache size to 40 MB as compared to 6 MB in V100 GPUs.
- Global memory—This is the framebuffer size of the GPU and DRAM sitting in the GPU. Each thread has private local memory. Each thread block has shared memory visible to all threads of the block and with the same lifetime as the block. All threads have access to the same global memory.
There are also two additional read-only memory spaces accessible by all threads: the constant and texture memory spaces.
Constant Memory
Declare and copies to constant memory
|
|
There are two reasons why reading from the 64KB of constant memory can save bandwidth over standard reads of global memory:
- Asinglereadfromconstantmemorycanbebroadcasttoother“nearby” threads, effectively saving up to 15 reads.
- Constantmemoryiscached,soconsecutivereadsofthesameaddresswillnot incur any additional memory traffic.
When it comes to handling constant memory, NVIDIA hardware can broadcast a single memory read to each half-warp. A half-warp—not nearly as creatively named as a warp—is a group of 16 threads: half of a 32-thread warp. If every thread in a half-warp requests data from the same address in constant memory, your GPU will generate only a single read request and subsequently broadcast the data to every thread. If you are reading a lot of data from constant memory, you will generate only 1/16 (roughly 6 percent) of the memory traffic as you would when using global memory.
But the savings don’t stop at a 94 percent reduction in bandwidth when reading constant memory! Because we have committed to leaving the memory unchanged, the hardware can aggressively cache the constant data on the GPU. So after the first read from an address in constant memory, other half-warps requesting the same address, and therefore hitting the constant cache, will generate no additional memory traffic.
The half-warp broadcast feature is in actuality a double-edged sword. Although it can dramatically accelerate performance when all 16 threads are reading the same address, it actually slows performance to a crawl when all 16 threads read different addresses. The trade-off to allowing the broadcast of a single read to 16 threads is that the 16 threads are allowed to place only a single read request at a time. For example, if all 16 threads in a half-warp need different data from constant memory, the 16 different reads get serialized, effectively taking 16 times the amount of time to place the request. If they were reading from conventional global memory, the request could be issued at the same time. In this case, reading from constant memory would probably be slower than using global memory.
Measuring Performance with Events
An event in CUDA is essentially a GPU time stamp that is recorded at a user- specified point in time.
|
|
|
|
|
|
Texture Memory
Like constant memory, texture memory is cached on chip, so in some situations it will provide higher effective bandwidth by reducing memory requests to off-chip DRAM. Specifically, texture caches are designed for graphics applications where memory access patterns exhibit a great deal of spatial locality. In a computing application, this roughly implies that a thread is likely to read from an address “near” the address that nearby threads read, as show in be below picture.
// these exist on the GPU side
texture<float> texConstSrc;
texture<float> texIn;
texture<float> texOut;
HANDLE_ERROR( cudaMalloc( (void**)&data.dev_inSrc, imageSize ) );
HANDLE_ERROR( cudaMalloc( (void**)&data.dev_outSrc, imageSize ) );
HANDLE_ERROR( cudaMalloc( (void**)&data.dev_constSrc, imageSize ) );
HANDLE_ERROR( cudaBindTexture( NULL, texConstSrc,
data.dev_constSrc,
imageSize ) );
HANDLE_ERROR( cudaBindTexture( NULL, texIn,
data.dev_inSrc,
imageSize ) );
HANDLE_ERROR( cudaBindTexture( NULL, texOut,
data.dev_outSrc,
imageSize ) );
Page-Locked Host Memory
There is a significant difference between the memory that malloc()
will allocate and the memory that cudaHostAlloc() allocates. The C
library function malloc() allocates standard, pageable host memory, while cudaHostAlloc() allocates a buffer of page-locked host memory. Sometimes called pinned memory, page-locked buffers have an important property: The operating system guarantees us that it will never page this memory out to disk, which ensures its residency in physical memory.
CUDA Streams
CUDA streams can play an important role in accelerating your applications. A cudA stream represents a queue of GPU operations that get executed in a specific order. We can add operations such as kernel launches, memory copies, and event starts and stops into a stream. The order in which operations are added to the stream specifies the order in which they will be executed. You can think of each stream as a task on the GPU, and there are opportunities for these tasks to execute in parallel.
|
|
cudaMemcpyAsync() this function executes synchronously, meaning that when the function returns, the copy has completed, and the output buffer now contains the contents that were supposed to be copied into it.
cudaMemcpyAsync() The call to cudaMemcpyAsync() simply places a request to perform a memory copy into the stream specified by the argument stream. When the call returns, there is no guarantee that the copy has even started yet, much less that it has finished. The guarantee that we have is that the copy will definitely be performed before the next opera- tion placed into the same stream. It is required that any host memory pointers passed to cudaMemcpyAsync() have been allocated by cudaHostAlloc().
Functions
__syncthreads()acts as a barrier at which all threads in the block must wait before any is allowed to proceed.
|
|
Optimization
Coalesced Access to Global Memory(合并内存访问)
假定GPU memory总线的宽度为256位,因为基于字节地址的总线要访问memory,必须和纵总线的宽度对齐,所以必须按32字节来访问memory。如果我们要访问地址0x00001232中的数据,GPU会同时得到0x00001220到0x0000123F的所有数据,如此其它28个字节的数据都浪费了,白白消耗了带宽。
为了利用总线带宽,GPU通常会把多个线程的访存合并到较少的内存请求中去,以此提高带宽的利用率。
|
|
C++ Language Extensions
Variable Memory Space Specifiers
Shared memory
|
|
__restrict__
Avoid aliasing issue.
|
|
Since the pointers a, b, and c may be aliasd, any write through c could modify elemets of a or b. The compiler cannot take advantage of the common sub-expression or reorder optimizations. By making a, b and c restricted pointers, the programmer assets to the compiler that the pointers are in fact not aliased. The compiler can now reorder and do common sub-expression elimination at will.
|
|
Built-in Vector Types
Basic types
These are vector types derived from the basic integer and floating-point types. They are structures and the 1st, 2nd, 3rd, and 4th components are accessible through the fields x, y, z, and w, respectively. They all come with a constructor function of the form make_<type name>; for example,
|
|
which creates a vector of type int2 with value(x, y).
This format support types char, short, int, long, longlong, float, double
Built-in Variables
Built-in variables specify the grid and block dimensions and the block and thread indices.
- gridDim: This variables is of type dim3 and contains the dimensions of the grid.
- blockldx: The variables if of type uint3 and contains the block index within the grid.
- blockDim: The variable is of type dim3 and contains the dimensions of the block.
- threadldx: This variables is of type uint3 and contains the thread index within the block.
- warpSize: This variable is of type int and contains the warp size in threads.
Memory Fence Functions
Memory fence funcitons can be used to enforce some ordering on mmeory accesses.
|
|
- All writes to all memory made by the calling thread before the call to __threadfence_block() are observed by all threads in the block of the calling thread as occurring before all writes to all memory made by the calling thread after the call to __threadfence_block();
- All reads from all memory made by the calling thread before the call to __threadfence_block() are ordered before all reads from all memory made by the calling thread after the call to __threadfence_block(). This function is used if threads belong to the same block.
|
|
acts as __threadfence_block() for all threads. This function is used if they are CUDA threads form the same device.
|
|
acts as __threadfence_block() for all threads in the device, host threads, and all thread in peer devices. This function is used if they are CUDA threads from two different devices. (This function is only supported by devices of compute capability 2.x and higher).
|
|
For this code, the following outcomes can be observed:
- A = 1, B = 2
- A = 10, B = 2
- A = 10, B = 20
Synchronization Functions
|
|
waits all threads in the thread block.
|
|
is identical to __syncthreads() with the additional feature that it evaluates predicate for all threads of the block and returns the number of threads for which predicate evaluates to non-zero.
|
|
is identical to __syncthreads() with the additional feature that it evaluates predicate for all threads of the block and returns non-zero if and only if predicate evaluates to non-zero for all of them.
|
|
is identical to __syncthreads() with the additional feature that it evaluates predicate for all threads of the block and returns non-zero if and only if predicate evaluates to non-zero for any of them.
|
|
will cause the executing thread to wait until all warp lanes named in mask have executed a __syncwarp() (with the same mask) before resuming execution. All non-exited threads named in mask must execute a corresponding __syncwarp() with the same mask, or the result is undefined.
Store Functions Using Cache Hints
|
|
内存
全局内存
CPU 主机端可以通过三种方式对GPU上的内存进行访问:
- 显式地阻塞传输
- 显式的非阻塞传输
- 隐式地使用零内存复制
GPU遵循一种惰性计算模型,只有在真正需要变量内容进行计算时才会到内存中取值。
Examples
vector dot product
- 最后用一个 sm 核进行求和
|
|
shared memory
|
|
该例子中是利用 shared memory 进行数组的反转。
其中采用了两种 shared memory 分配的方式,
- static shared memory
|
|
用于在编译时就已经知道需要分配的内存大小
- dynamic shared memory
|
|
动态的内存分配,需要在启动 kernel 函数时在配置 <<>>> 内进行设置。且声明需要是如下方式:
|
|
如果想通过该方式声明多个 shared memory ,则是在配置时设置一个连续的大内存空间,然后在分别使用
|
|