Parameter Server (Async SGD)
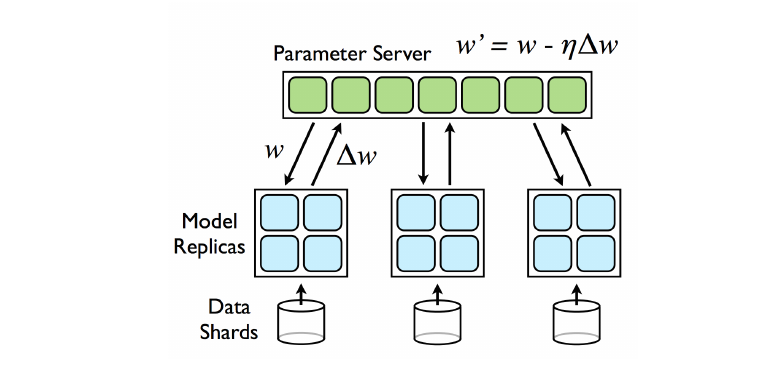 数据被切分至各个worker,所有的worker都拥有整个模型。在每次迭代过程中,master只要接受到worker发送来的梯度信息$\Delta W_i$即更新权重,然后发送更新后的权重信息给该worker。所有的worker都进行异步的更新,master采用先来先服务的策略(first come first serve FCFS)[1]。
数据被切分至各个worker,所有的worker都拥有整个模型。在每次迭代过程中,master只要接受到worker发送来的梯度信息$\Delta W_i$即更新权重,然后发送更新后的权重信息给该worker。所有的worker都进行异步的更新,master采用先来先服务的策略(first come first serve FCFS)[1]。
Hogwild (Lock Free)
Hogwild[2]是Async SGD的一个变种。在Async SGD中其实是存在一个锁的,即如果worker j在worker i还在master中进行权重更新的时候就已经到来,在Async SGD中的做法是必须等到worker i更新完后才能进行worker j才能进行处理,即一次只能处理一个worker的梯度信息。但是在Hogwild方法中,则是去除掉了这个锁的限制,使得master可以同时处理多个worker提供的梯度信息,且该方法时被证明可以收敛的[2]。
EASGD (Round-Robin)
EASGD[3]也是Async SGD的一个变种。在Async SGD中采用的FCFS的策略异步的处理各个workre发送的梯度信息。在EASGD使用round-robin的策略来进行有序的更新,即$W = W - \eta \Delta W_i$不能在$W = W - \eta \Delta W_{i - 1}$之前进行。
