MONARCH: Hierarchical Storage Management for Deep Learning Frameworks
 该论文通过利用计算节点的本地存储(eg,SSD),作为一个数据缓存,以达到减轻数据访问是对 PFS(eg,Luster 文件系统)的访问压力及减轻网络负载。
该论文通过利用计算节点的本地存储(eg,SSD),作为一个数据缓存,以达到减轻数据访问是对 PFS(eg,Luster 文件系统)的访问压力及减轻网络负载。
Operation Flow:
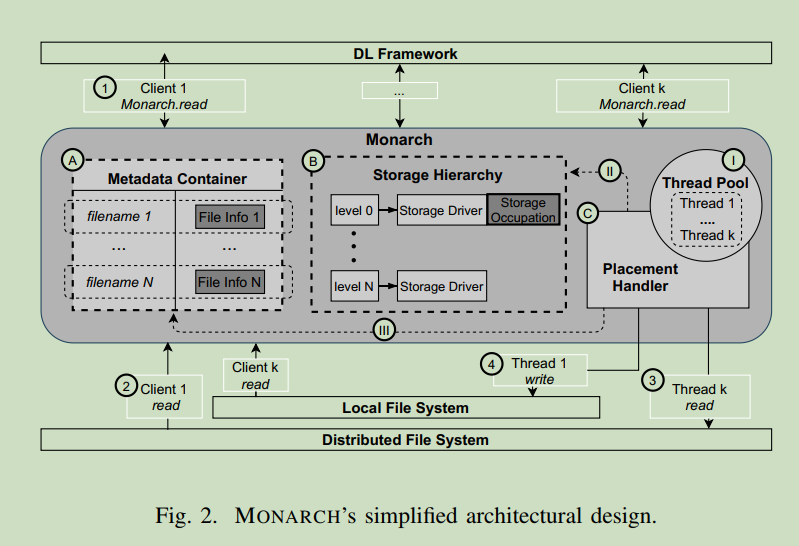
At execution time, upon a read request made to a file X by the DL framework with the intent of reading a small portion of the file, MONARCH intercepts the request and verifies at the metadata container module which storage level where file X is placed/stored ( 1 ). Having this information, the read request is forwarded to the corresponding storage driver (i.e., level 1) and submitted to the respective storage backend ( 2 ). After completing the request, the retrieved content is served back to the DL framework.
At the same time, MONARCH utilizes one of the thread pool’s background threads ( I ) to perform the data placement of X. First, the placement handler ( C ) determines the level where X should be placed. It does so by hierarchically traversing the storage tiers ( II ), searching for the first one that has enough space to store the fetched content. In this case, level 0 is picked. At that time, another request is submitted to the thread pool to perform a copy of the file from level 1 to level 0 (operations 3 and 4 ). As explained previously, this mechanism copies the full content of the file so that subsequent read requests can be served from a faster storage tier. An independent thread performs this to avoid delaying the retrieval of the partial content requested by the DL framework. If the DL framework had requested the full content of the file operation, event 3 would not happen, and MONARCH would copy the content read in 2 and place it on level 0 ( 4 ). Finally, the file storage level is updated to 0 ( III ) and the storage occupation of level 0 ( II ) is updated.
Contribution: Its primary purpose is to move data samples from the shared and performance-expensive remote storage to the compute node’s local device to reduce the DL training time as well as the I/O pressure imposed over the PFS. To ensure transparency to users, and to not conflict with I/O-oriented optimizations already implemented at the DL framework (e.g., data shuffling, caching and prefetching, I/O parallelism), MONARCH resides at the POSIX layer, thus not impacting the internal operation model of the targeted framework. It achieves this by exposing a simple API composed by a custom read operation that replaces the traditional POSIX read system call used by DL frameworks. Such an API enables straightforward integration with different DL frameworks, as it requires minimal code changes, maintaining MONARCH’s design generic and portable.
CHFS: Parallel Consistent Hashing File System for Node-local Persistent Memory
This paper proposes a design for CHFS, an ad hoc parallel file system that utilizes the persistent memory of compute nodes. The design is based entirely on a highly scalable distributed key-value store with consistent hashing.
CHFS implementation is based on Mochi-Margo library and Pmemkv.
MochiMargo is a library of network services based on the Mercury communication library [30] for remote procedure call (RPC) and RDMA, and Argobots lightweight thread library [28]. Mochi-Margo provides a blocking RPC programming interface while implicitly using a progress loop for communication and callbacks to nonblocking communications. Mochi-Margo efficiently supports an event-driven execution model in Mercury and lightweight multithread execution. Mercury, in turn, supports several network layers including tcp, verbs, psm2 (Omni-Path), and gni (Gemini/Aries) provided by libfabric.
Pmemkv is a library for a persistent in-memory key-value store.
BeeGFS
BeeGFS transparently spreads user data across multiple servers. By increasing the number of servers and disks in the system, you can simply scale performance and capacity of the file system to the level that you need, seamlessly from small clusters up to enterprise-class systems with thousands of nodes. Similar to the Lustre file system, BeeGFS separates data services and metadata services. When a client has received the metadata information from the metadata servers, it can directly access the data. Unlike traditional NAS systems, this provides for higher performance.
Disadvantages of BeeGFS
BeeGFS is an open source project which is designed to cater to academic HPC environments, but it lacks many of the features required in an enterprise environment. The following provides a summary of limitations that BeeGFS suffers from:
- Does not support any kind of data protection such as erasure coding or distributed RAID.
- Does not have file encryption, at rest or on-the-fly
- No native support NVMe-over-Fabric. Need to pay extra for 3rd-party NVMe-over-Fabric layer
- Needs separate management and metadata servers
- Limited by legacy storage interfaces such as SAS, SATA, FC
- Does not support enterprise features such as snapshots, backup, data tiering,
- Does not support enterprise protocols such as Network File System (NFS) or SMB (requires separate services)
GekkoFS
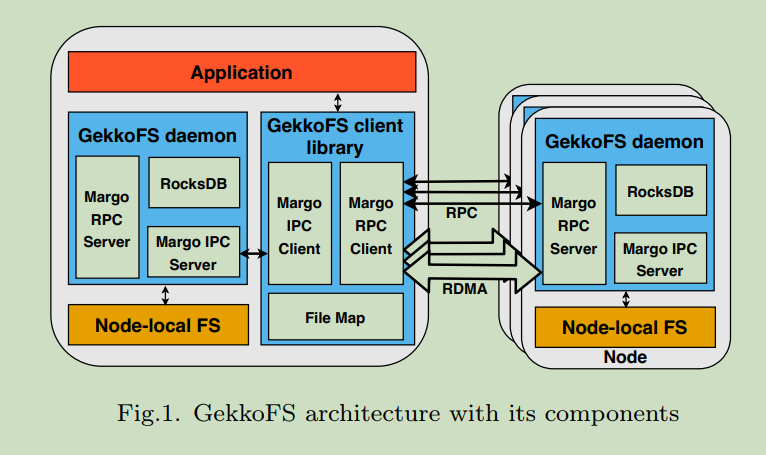
GekkoFS client
The client consists of three components:
- An interception interface that catches relevant calls to GekkoFS and forwards unrelated calls to the node-local file system;
- A file map that manages the file descriptors of opened files and directories, independently of the kernel;
- An RPC-based communication layer that forwards file system requests to local/remote GekkoFS daemons.
While a file is open, the client uses the file path $p$ for each related file system operation to determine the GekkoFS daemon node that should process it. Specifically, the path $p$ is hashed using a hash function $h$ to resolve the responsible daemon for an operation by calculating: $$ nodeID = h(p)\ (mod\ number\ of\ GekkoFS\ nodes) $$
In addition, to achieve a balanced data distribution for large files, data requests are split into equally sized chunks before they are distributed across file system nodes.
GekkoFS daemon
A GekkoFS daemon’s purpose is to process forwarded file system operations of clients to store and retrieve data and metadata that hashes to a daemon. To achieve this goal, GekkoFS daemons consist of three parts:
- A key-value store (KV store) used for handling metadata operations.
- An I/O persistence layer that reads/writes data from/to the underlying node-local storage system.
- an RPC-based communication layer that accepts local and remote connections to handle file system operations.
Data management
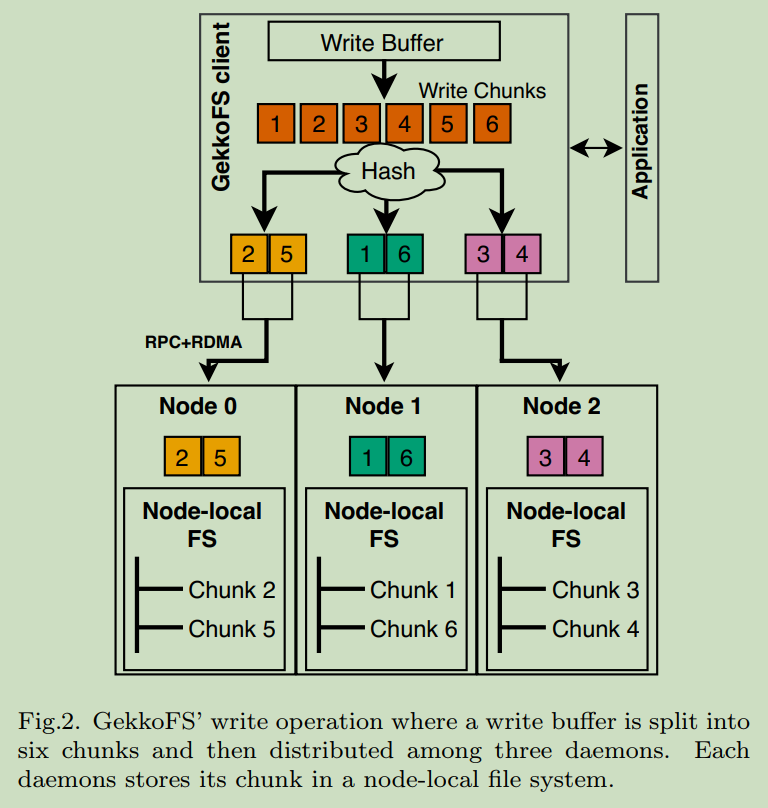
Within a node-local file system, each chunk is represented as a file and is named after the chunk’s numeric identifier, which also describes the chunk’s data offset. In the given case, the write buffer is split into six chunks (dependent on the chunk size). For each chunk, GekkoFS computes the target node with the help of the file’s path and chunk identifier, grouping chunks that target the same node. The client then sends an RPC message to each target daemon node, each independently handling the write request for a group of chunks.
Each GekkoFS daemon accesses the client’s memory via RDMA and writes the corresponding chunks to its node-local file system. If the target daemon refers to the local machine, data is moved via CMA, which allows accessing a set memory region of another process on the same machine without copying it.
Shared write conflicts
GekkoFS does not implement a global locking manager. This can impose challenges when working with shared files. For instance, when two or more processes write to the same file region at the same time they could cause a shared write conflict, resulting in an undefined behavior with regards to the data which is written to the underlying storage device.