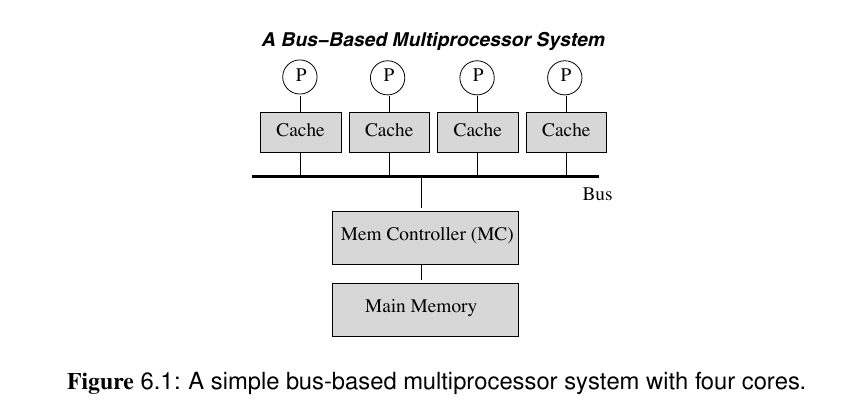
共享存储多处理器
缓存一致性问题
 假定我们要执行以下代码,将
假定我们要执行以下代码,将a[0]与a[1]相加保存之变量sum中:
|
|
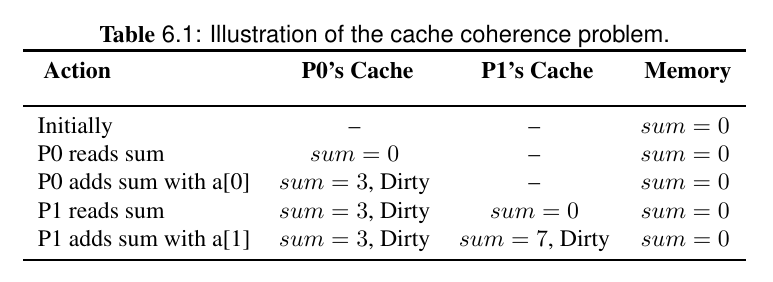 假定每个处理器都有一个高速缓存,且采用写回策略(write back cache)。初始时,线程0从sum地址读取数值至寄存器,这就导致了sum的存储块被缓存到处理器0中,之后线程0执行加指令将sum与a[0]相加。相加的结果仍然保存在寄存器中,之后通过store指令写回sum所在的存储地址。由于包含sum的存储块已经被缓存,缓存修改后的脏位会被设置,同时主存中仍然保存着已经过时的存储块sum=0.当线程1从主存中读取sum时,它将看到sum的值为0,然后将a[1]与sum相加,结果保存在缓存之中。最终,当线程0读取sum的值时,将会直接读取缓存中的值(缓存命中),那么他将得到sum的值为3.
假定每个处理器都有一个高速缓存,且采用写回策略(write back cache)。初始时,线程0从sum地址读取数值至寄存器,这就导致了sum的存储块被缓存到处理器0中,之后线程0执行加指令将sum与a[0]相加。相加的结果仍然保存在寄存器中,之后通过store指令写回sum所在的存储地址。由于包含sum的存储块已经被缓存,缓存修改后的脏位会被设置,同时主存中仍然保存着已经过时的存储块sum=0.当线程1从主存中读取sum时,它将看到sum的值为0,然后将a[1]与sum相加,结果保存在缓存之中。最终,当线程0读取sum的值时,将会直接读取缓存中的值(缓存命中),那么他将得到sum的值为3.
如果将cache策略改为写直达(write through caches)的话,结果仍然不正确。因为当线程0更新sum的时候,该更新会传播到主存中。因此,当线程1从主存中读取sum时,将会读到正确值3,之后线程1将sum与7相加得到正确结果,这时sum为正确值10.然而,当线程0打印sum值的时候,会发现处理器0的缓存已有sum的有效副本(缓存命中),其打印的值是3(尽管主存中的sum具有最新值10)。
缓存一致性问题需要将同一个地址上的值的修改从一个高速缓存中传播到其它高速缓存,并且将这些修改串行化。 缓存一致性是通过被称为缓存一致性协议机制来实现的,为了保证缓存一致性协议的正确性,需要实现写传播和事务串行化。
写传播是指多个处理器对相同数据的写操作能够以正确的方式相叠加。
存储一致性问题
存储一致性主要用于解决对不同存储地址的所有存储操作(load and store)的排序问题。
考虑以下代码,信号-等待同步:

在单处理器系统上,代码执行嗯的正确性取决于S1语句是否在S2语句之前被执行。由于当今的典型处理器都实现了乱序执行机制,该机制仍然保留依赖(数据和控制流)和指令提交的程序顺序。对于S1和S2中的store指令既没有数据依赖,又没有控制流依赖,所以S2可能在S1之前执行。但是由于单处理器实现了顺序指令提交,这就保证了S1在S2之前执行。在C/C++中告诉编译器保留程序顺序的做法是:将datumIsReady声明为volatile类型,编译器就会指导对该变量继续的load或者store操作不能被移除,也不能与其之前和之后的指令调换顺序。
在多处理器系统中,则需要额外的相关机制来保证对单个处理器的访问在其他所有处理器看来都是按照程序顺序进行的。