Gandiva: introspective cluster scheduling for deep learning[1]
Observation
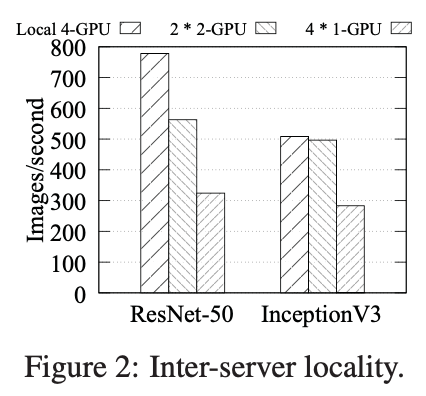
- Sensitivity to locality: 使用多个 GPU 的深度学习训练任务的性能取决于所分配 GPU 的相近性(affinnity), 比如:两个GPU可能放置在不同的 CPU sockets上、在同一个 CPU sockets 但是在不同的 PCIe switches、或者在同一个 PCIe switch。
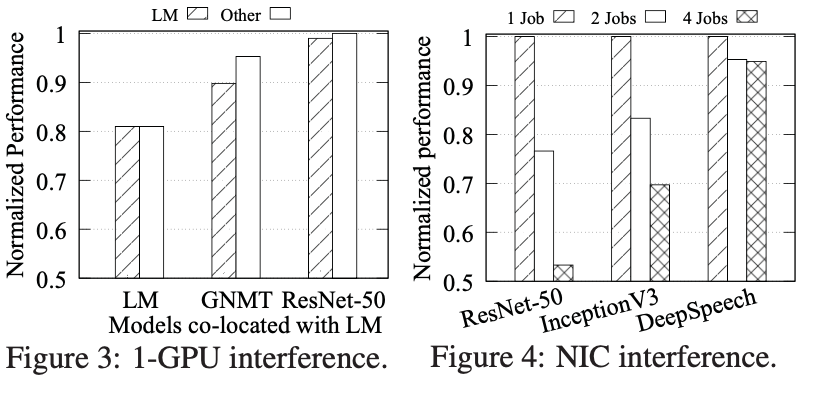
- Sensitivity to interference: 当运行在共享资源的环境下,多个训练任务之间会存在干扰,并且对于不同类型(比如图像识别,NLP等)的任务干扰的程度不一样。
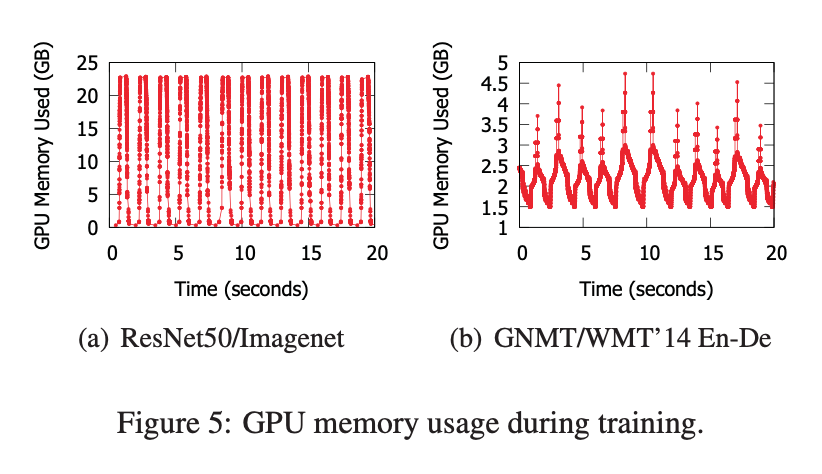
- Intra-job predictability: 训练都是以迭代的方式用一个 batch 的数据作为输入进行训练,使得 GPU 内存的使用存在可预测的周期性。利用该特性我们可以采取 suspend/resume , packing, migration 的操作。
Machanisms
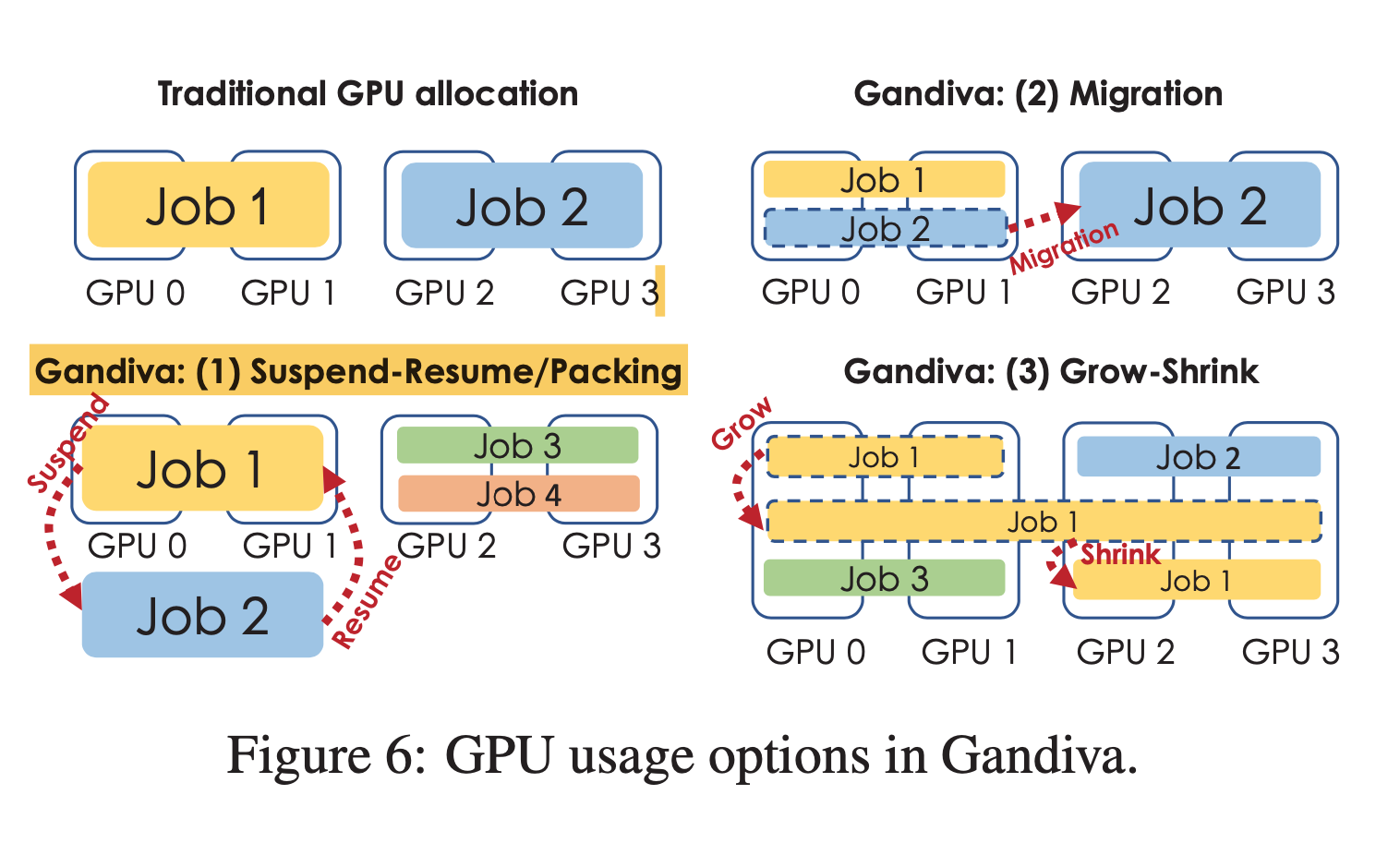
为了提高 GPU 的利用率,Gandiva 解除了训练任务独占 GPU 的限制。 并采用如下三种方法
- 让新来的训练任务可以通过 time-share 的方式与现有的任务共同执行 (利用 suspend-resume, packing 这两种机制进行实现)
- 允许任务高效的迁移到不同的 GPU 上执行,比如迁移到更相近 ( good locality ) 的一些 GPU 上执行
- 采用 grow-shrink 机制让空闲的 GPU 有机会被使用起来。
下面详细介绍实现以上功能所采用方式
-
Suspend-Resume: 类似于 CPU 的分时服用的想法。 suspend-resume 的关键在于利用训练任务内存占用的周期性,suspend 操作会在内存占用最低的时候,将对象数据从 GPU 搬到 CPU 然后释放 GPU 的内存。当 resume 时,会首先分配好相应的 GPU 内存之后从 CPU 复制数据回 GPU。
-
Packing: 在多个任务的资源占用不操作 GPU 所有的资源 ( cores, memeory ) ,让多个训练任务同时在 GPU 上执行,叫做 packing. 需要注意的是多个任务执行时可能会出现会想干扰导致性能还不如利用 suspend-resume 策略。
-
Migration: 指将训练任务迁移到不同的 GPUs 上进行执行。migration 在以下情况适合使用:1. 将 time-sliced jobs 迁移至释放出来空闲的GPU 2. 将互相干扰的任务进行迁移 3. 为新来的任务腾出空位使得拥有 good locality.
-
Grow-Shrink: 对于一些训练任务,比如在图像领域,存在使用的 GPUs 越多,性能可以线性增长。所以对这种类型的任务, 我们可以恰当的进行扩展使用更多的 GPUs 或者缩减其使用的 GPUs. 对于该训练任务是否支持该特性需要用户进行标识告知。
Scheduling Policy
Gandiva 调度器采用了两种模式:reactive (用于 job arrivals, job departures, machine failures etc.)和 intorspective (持续的过程,来提供 GPUs 的利用率和 加快任务的完成时间)。整体来说,调度策略比较简单,详情参考论文。