方法
k-means算法是一种聚类算法,所谓聚类,即根据相似性原则,将具有较高相似度的数据对象划分至同一类簇,将具有较高相异度的数据对象划分至不同类簇。
算法流程:
- 选择聚类的个数k(kmeans算法传递超参数的时候,只需设置最大的K值)
- 任意产生k个聚类,然后确定聚类中心,或者直接生成k个中心。
- 根据中心划分类簇
- 根据新生成的类簇再计算其聚类新中心
- 重复以上步骤直到满足收敛要求。(eg. 中心点不再改变。)
并行化
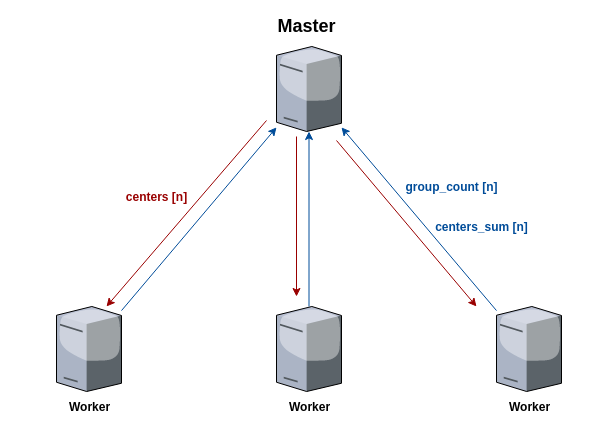
算法流程:
- 各计算节点获取相应的样本数量
- master节点初始化k个聚类中心,然后广播给各节点
- 各节点基于中心点,对本地数据进行类簇的划分
- 各节点根据新划分的类簇,计算同一类簇的和得到center_sum
- 各worker节点统计类簇大小group_count,并将group_count 和center_sum发送给master
- master 根据接收到的center_sum和group_count计算新的中心点,然后发送给个节点
- 重复以上步䠫直至收敛