MPI Notes
语法
-
MPI_Send(msg_buf_p, msg_size, msg_type, dest, tag, communicator)MPI_Send的精确行为由实现决定:可能当消息大于一个阈值,该函数将被阻塞,小于该值将被缓冲。若信息没有被正确接受,信息将会丢失或者该进程被悬挂。 -
int MPI_Isend(const void* buf, int count, MPI_Datatype datatype, int dest,int tag, MPI_Comm comm, MPI_Request *request) -
MPI_Recv(msg_buf_p, buf_size, buf_type, source, tag, communicator, status_p)其中 source 可以赋值为一个特殊的常量
MPI_ANY_TAG,即可以接受任意源的信息。特殊常量MPI_ANY_TAG可以接受任意 tag 的信息。该函数调用即被阻塞。如果没有相匹配的信息接受,该进程将被悬挂。对于status_p可以使用MPI_STATUS_IGNORE -
int MPI_Irecv(void* buf, int count, MPI_Datatype datatype, int source,int tag, MPI_Comm comm, MPI_Request *request) -
int MPI_Get_count(status_p, type, count_p)获取接收到的数据量大小
-
int MPI_Reduce(input_data_p, output_data_p,count, datatype, operator, dest_process, comm)如果
count大于1,可以用于向量进行操作。operator归约操作符。输入地址与输出地址不能一样,非法 。 -
int MPI_Allreduce(input_data_p, output_data_p, count, datatype, operator, comm)所有的进程都获得全局操作后的结果。在input_data_p使用
MPI_IN_PLACE可以在input_data_p的存储位置放置结果内容。支持的操作:
- MPI_MAX : maximum
- MPI_MIN : minimum
- MPI_SUM : sum
- MPI_PROD : product
- MPI_LAND : logical and
- MPI_BAND : bit-wise and
- MPI_LOR : logical or
- MPI_BOR : bit-wise or
- MPI_LXOR : logical exclusive or (xor)
- MPI_BXOR : bit-wise exclusive or (xor)
- MPI_MAXLOC : max value and location
- MPI_MINLOC : min value and location
-
int MPI_Bcast(dta_p, count, datatype, source_proc, comm)广播数据
-
int MPI_Scatter(send_buf_p, send_count, send_type, recv_buf_p, recv_count, recv_type, src_proc, comm)会将
send_buf_p上的数据分成comm_sz份,依次发送给这些进程。该方法适用于块划分法,且向量的分量个数n可以整除comm_sz的情况。send_count表示的是发送给每个进程的数据量。每个进程必须发送或者接受同样数量的数据。 -
MPI_SCATTERV(sendbuf, sendcounts, displs, sendtype, recvbuf, recvcount, recvtype, root,comm)实现将不同数量的数据发送之各个进程
-
int MPI_Gather(send_buf_p, send_count, send_type, recv_buf_p, recv_count, recv_type, dest_proc, comm)将向量的所有分量搜集至目标进程。每个进程必须发送或者接受同样数量的数据。
-
int MPI_Allgather(send_buf_p, send_count, send_type, recv_buf_p, recv_count, recv_type, comm)将每个进程的
send_buf_p的内容串联起来,存储到每个进程的rcv_buf_p参数中,相当于进行了一次MPI_Gather后在调用MPI_Bcast -
int MPI_Type_create_struct(int count, int array_of_blocklengths[], array_of_displacements[], array_of_types[], array_of_types[], new_type_p)用于构建由不同基本数据类型的元素所组成的派生数据类型
-
int MPI_Get_address(location_p, address_p)返回的是
location_p所指向的内存单元的地址 -
int MPI_Type_ccommit(new_mpi_t_p)允许MPI实现为了在通信函数内使用这一新创建的数据类型
-
int MPI_Type_free(old_mpi_t_p)当使用完新的数据类型时,可用该函数去释放额外的存储空间
-
double MPI_Wtime(void)返回从过去某一时刻开始所经过的秒数
-
int MPI_Barrier(MPI_Comm comm)确保同一个通信子中的所有进程都完成调用该函数之前,没有进程能够提前返回。
-
int MPI_Wait(MPI_Request *request, MPI_Status *status) -
int MPI_Waitall(int count, MPI_Request array_of_requests[], MPI_Status array_of_statuses[]) -
MPI_Waitany(count, requests, index, status) -
MPI_Waitsome(count, requests, done, index, status) -
int MPI_Comm_create(MPI_Comm comm, MPI_Group group, MPI_Comm *newcomm)按照group中的进程构建新的通信域
-
int MPI_Comm_dup(MPI_Comm comm, MPI_Comm *newcomm)复制通信域
-
int MPI_Group_translate_ranks(MPI_Group group1, int n, const int ranks1[], MPI_Group group2, int ranks2[])用于已知该进程在原通信域的rank,想知道该进程在另一个通信域上的rank.
-
int MPI_Comm_free(MPI_Comm *comm)释放通信域的资源
-
int MPI_Win_create(void *base, int size, int disp_unit, MPI_Info info,MPI_Comm comm, MPI_Win *win)创建RMA操作的内存空间窗口“window”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18int main(int argc, char ** argv) { int *a; MPI_Win win; MPI_Init(&argc, &argv); /* create private memory */ MPI_Alloc_mem(1000*sizeof(int), MPI_INFO_NULL, &a); /* use private memory like you normally would */ a[0] = 1; a[1] = 2; /* collectively declare memory as remotely accessible */ MPI_Win_create(a, 1000*sizeof(int), sizeof(int), MPI_INFO_NULL, MPI_COMM_WORLD, &win); /* Array ‘a’ is now accessibly by all processes in * MPI_COMM_WORLD */ MPI_Win_free(&win); MPI_Free_mem(a); MPI_Finalize(); return 0; } -
int MPI_Win_allocate(MPI_Aint size, int disp_unit,MPI_Info info,MPI_Comm comm, void *baseptr, MPI_Win *win)开辟一块空间并创建RMA操作的窗口
1 2 3 4 5 6 7 8 9 10 11 12 13int main(int argc, char ** argv) { int *a; MPI_Win win; MPI_Init(&argc, &argv); /* collectively create remote accessible memory in a window */ MPI_Win_allocate(1000*sizeof(int), sizeof(int), MPI_INFO_NULL, MPI_COMM_WORLD, &a, &win); /* Array ‘a’ is now accessible from all processes in * MPI_COMM_WORLD */ MPI_Win_free(&win); MPI_Finalize(); return 0; } -
int MPI_Win_create_dynamic(MPI_Info info, MPI_Comm comm, MPI_Win *win)创建RMA操作窗口,未来再分配内存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18int main(int argc, char ** argv) { int *a; MPI_Win win; MPI_Init(&argc, &argv); MPI_Win_create_dynamic(MPI_INFO_NULL, MPI_COMM_WORLD, &win); /* create private memory */ a = (int *) malloc(1000 * sizeof(int)); /* use private memory like you normally would */ a[0] = 1; a[1] = 2; /* locally declare memory as remotely accessible */ MPI_Win_attach(win, a, 1000*sizeof(int)); /* Array ‘a’ is now accessible from all processes */ /* undeclare remotely accessible memory */ MPI_Win_detach(win, a); free(a); MPI_Win_free(&win); MPI_Finalize(); return 0; } -
MPI_Put(void *origin_addr, int origin_count, MPI_Datatype origin_dtype, int target_rank, MPI_Aint target_disp, int target_count, MPI_Datatype target_dtype, MPI_Win win)从原进程移数据到目标进程
-
MPI_Get(void *origin_addr, int origin_count,MPI_Datatype origin_dtype, int target_rank,MPI_Aint target_disp, int target_count,MPI_Datatype target_dtype, MPI_Win win)从目标进程获取数据至原进程
-
MPI_Accumulate(void *origin_addr, int origin_count,MPI_Datatype origin_dtype, int target_rank,MPI_Aint target_disp, int target_count,MPI_Datatype target_dtype, MPI_Op op, MPI_Win win)执行聚合操作,结果放置目标进程
-
MPI_Get_accumulate(void *origin_addr, int origin_count,MPI_Datatype origin_dtype, void *result_addr,int result_count, MPI_Datatype result_dtype,int target_rank, MPI_Aint target_disp,int target_count, MPI_Datatype target_dype,MPI_Op op, MPI_Win win)执行聚合操作,结果放置原进程
-
MPI_Fetch_and_op(void *origin_addr, void *result_addr,MPI_Datatype dtype, int target_rank,MPI_Aint target_disp, MPI_Op op, MPI_Win win) -
MPI_Compare_and_swap(void *origin_addr, void *compare_addr,void *result_addr, MPI_Datatype dtype, int target_rank,MPI_Aint target_disp, MPI_Win win) -
int MPI_Init_thread(int *argc, char ***argv, int required, int *provided)- MPI_THREAD_SINGLE Only one thread will execute.
- MPI_THREAD_FUNNELED The process may be multi-threaded, but the application must ensure that only the main thread makes MPI calls (for the definition of main thread, see MPI_IS_THREAD_MAIN on page 488).
- MPI_THREAD_SERIALIZED The process may be multi-threaded, and multiple threads may make MPI calls, but only one at a time: MPI calls are not made concurrently from two distinct threads (all MPI calls are “serialized”).
- MPI_THREAD_MULTIPLE Multiple threads may call MPI, with no restrictions.
-
int MPI_Get_processor_name(char *name, int *resultlen)
|
|
This routine returns the name of the processor on which it was called at the moment of the call.
int MPI_Win_allocate_shared(MPI_Aint size, int disp_unit, MPI_Info info, MPI_Comm comm, void *baseptr, MPI_Win *win)

- called collectively by processes in comm
- processes in comm must be those that can access shared memory(e.g., processes on the same compute node)
- by default, a contiguous region of memory is allocated and shared (noncontiguous allocation is also possible, and may be more efficient as each contributed region could be page aligned)
- each process contributes size bytes to the contiguous region; size can be different for each process and can be zero
- the contribution to the shared region is in order by rank
- baseptr is the pointer to a process’s contributed memory (not the beginning of the shared region) in the address space of the process
how it work:
- Process with rank 0 in comm allocates the entire shared memory region for all processes
- Other processes attach to this shared memory region
- The entire memory region may reside in a single locality domain, which may not be desirable
- Therefore, using noncontiguous allocation may be advantageous
This is a collective call executed by all processes in the group of comm. On each process i, it allocates memory of at least size bytes that is shared among all processes in comm, and returns a pointer to the locally allocated segment in baseptr that can be used for load/store accesses on the calling process. The locally allocated memory can be the target of load/store accesses by remote processes; the base pointers for other processes can be queried using the function MPI_WIN_SHARED_QUERY.
int MPI_Win_shared_query(MPI_Win win, int rank, MPI_Aint *size, int *disp_unit, void *baseptr)

- baseptr returns the address (in the local address space) of the beginning of the shared memory segment contributed by another process, the target rank
- also returns the size of the segment and the displacement unit
- if rank is MPI_PROC_NULL, then the address of the beginning of the first memory segment is returned
- this function could be useful if processes contribute segments of different sizes (so addresses cannot be computed locally), or if noncontiguous allocation is used
- in many programs, knowing the “owner” of each segment may not be necessary
MPI_Probe(int source, int tag, MPI_Comm comm, MPI_Status* status)You can think of MPI_Probe as an MPI_Recv that does everything but receive the message .
|
|
多条信息整合
-
不同通信函数中的count参数
-
派生数据类型
一个派生数据类型是由一系列的MPI基本数据类型和每个数据类型的偏移所组成的
{(MPI_DOUBLE, 0), (MPI_DOUBLE, 16), (MPI_INT, 24)}每一对数据项的第一个元素表明数据类型,第二个元素是该数据项相对于起始位置的偏移。
-
MPI_Pack / Unpack
-
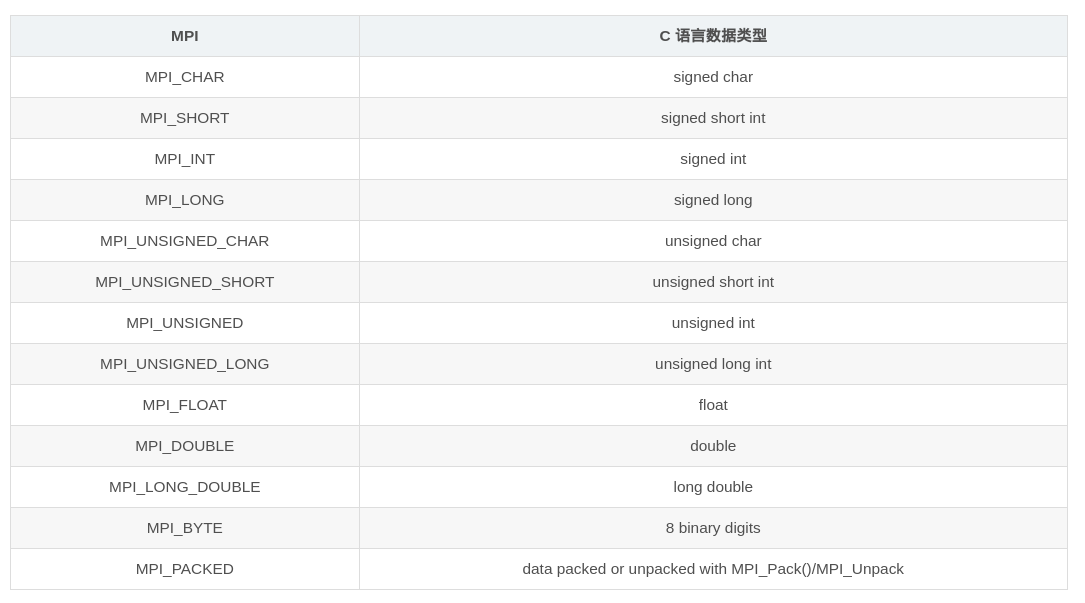
基础数据类型
|
|
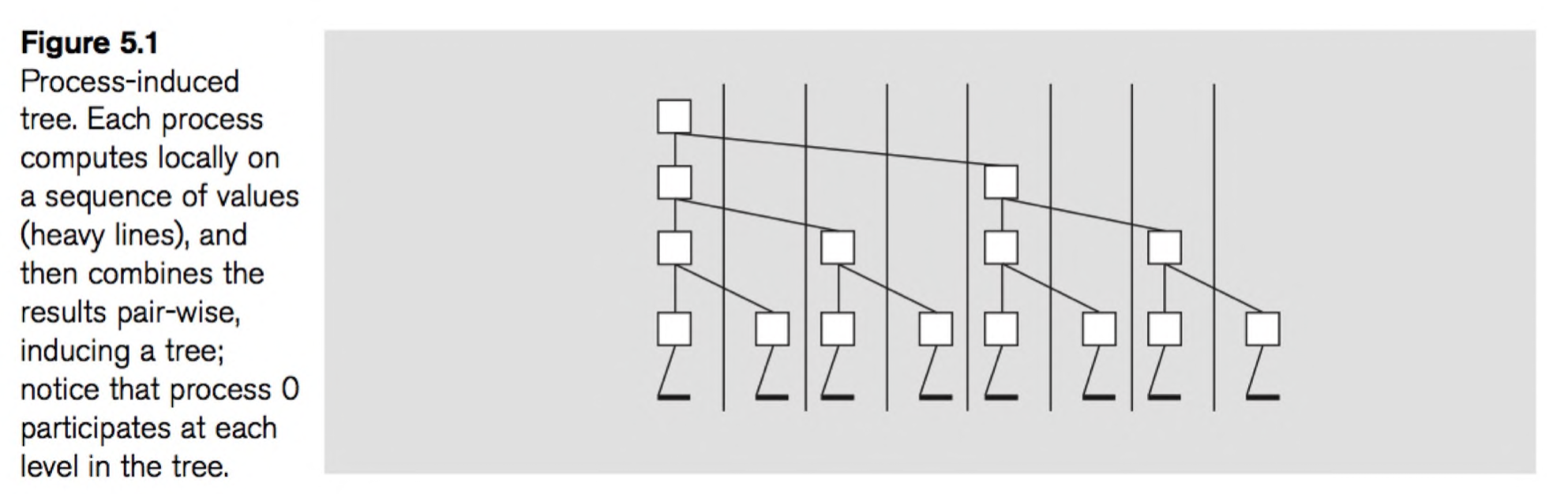
实现树形reduce
|
|
常用函数
MPI_Wtime()返回过去某一时刻开始所经过的秒数
常用代码块
新建通信域
|
|
Intra-node communicator
|
|
|
|
异步通信
|
|
|
|
Send with dynamic length.
|
|
MPI RMA


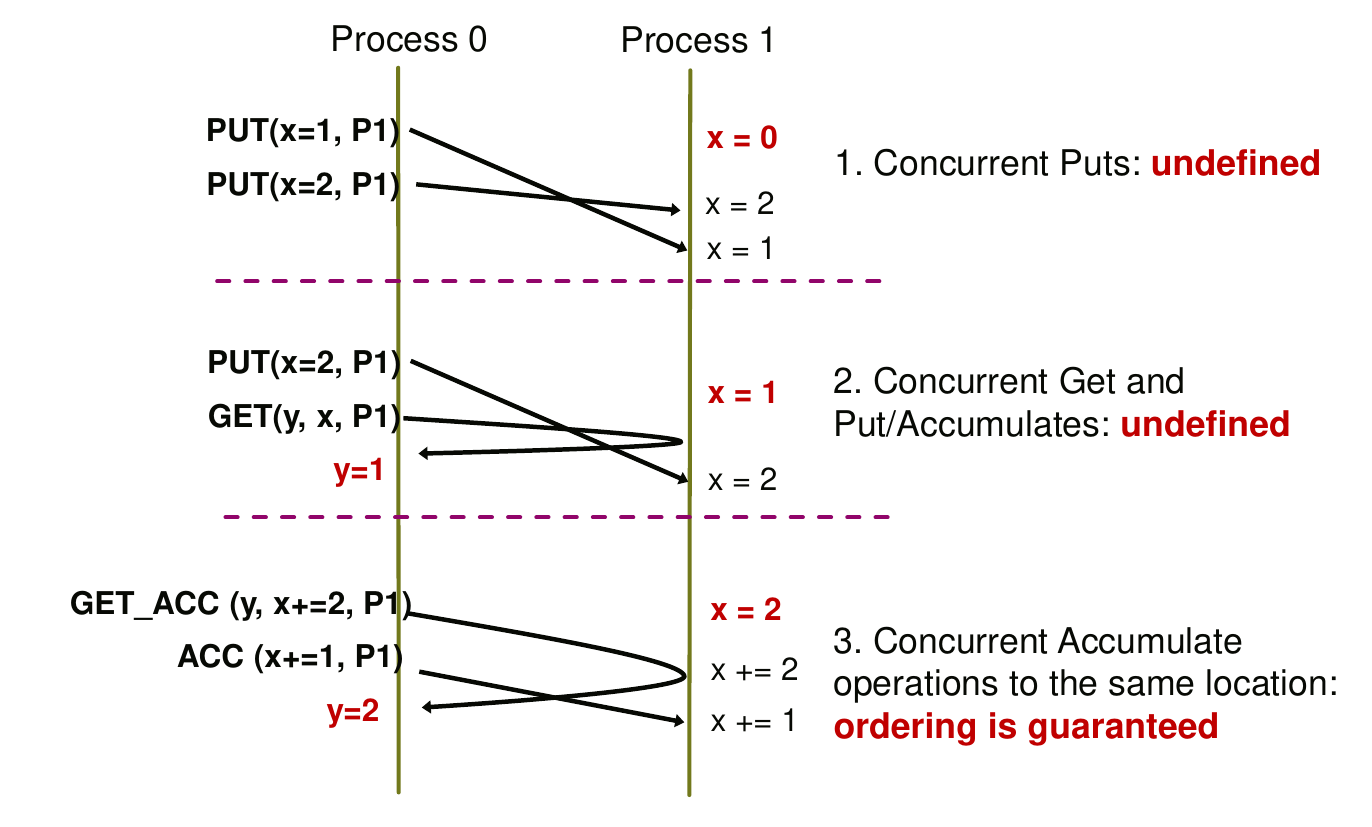 对于Put/Get操作的先后顺序没有保证。
对于Put/Get操作的先后顺序没有保证。
MPI提供的三种同步模型:
-
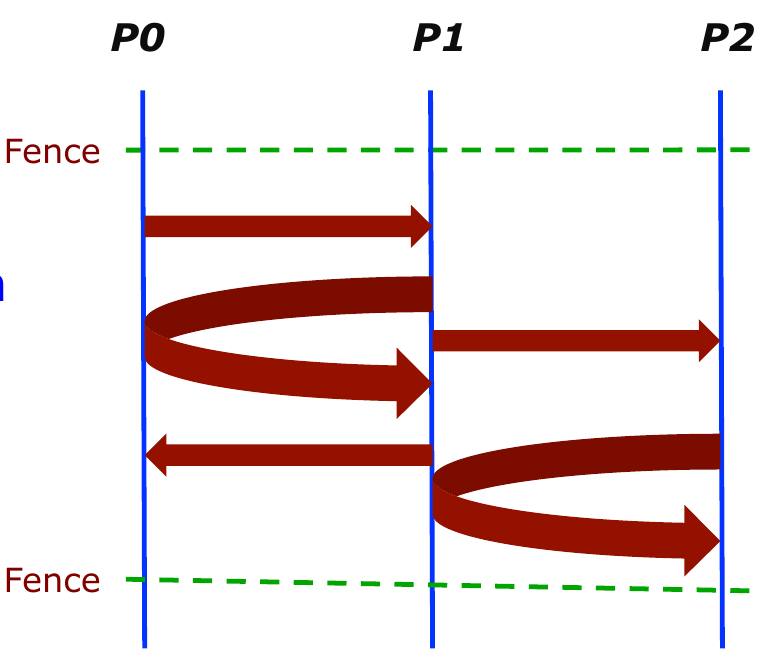
Fence:
MPI_Win_fence(int assert, MPI_Win win)所有进程的操作(Put/Get等)会在第二次调用fence前完成。两次epoch调用之间称为一个epoch
|
|
-
Post-start-complete-wait (generalized active target)
MPI_Win_post/start(MPI_Group grp, int assert, MPI_Win win)MPI_Win_complete/wait(MPI_Win win)
|
|
- Lock/Unlock (passive target)
|
|
Examples
Eigen matrix
|
|
RMA example
|
|
passive example
|
|
Shared-memory
|
|
MPI_MAXLOC 使用
|
|
若是出现 两个进程内的 val 值相等,则 MPI 会继续比较 rank 的值选取 rank 值更小的。
mpi 支持的类型
| support type | description |
|---|---|
| [ MPI_FLOAT_INT] | float and int |
| [ MPI_DOUBLE_INT] | double and int |
| [ MPI_LONG_INT] | long and int |
| [ MPI_2INT] | pair of int |
| [ MPI_SHORT_INT] | short and int |
| [ MPI_LONG_DOUBLE_INT] | long double and int |
MPI-IO
|
|
需要注意MPI_File_open和MPI_File_close是collective operation.
常用函数
- Function for determining which ranks are common to a compute node:
|
|
- Function for mapping group ranks to global ranks:
|
|
注意
-
大部分MPI实现只允许MPI_COMM_WORLD的0号进程访问标准输入stdin
-
P2P通信函数
MPI_Send,MPI_Isend,MPI_Recv,MPI_Irecv可以混合使用。比如可以使用MPI_Recv接收MPI_Isend发的数据。 -
在使用异步通信的时候使用
MPI_Barrier函数只能保证所有的进程都执行到这里跟数据的收发是否完成没有关系。要保证和检测异步通信的"完成"需使用MPI_Wait,MPI_Test。对于MPI_Isend, 其中的“完成”并不是只整个通信完成(可能数据被缓冲到系统的buffer了),只是表明发送数据的地址可以被重用。对于MPI_Irecv, 其中“完成”是指用来接收的buffer收到了信息,可以访问信息了。
内存泄漏检测
安装软件
|
|
使用
|
|