Basis
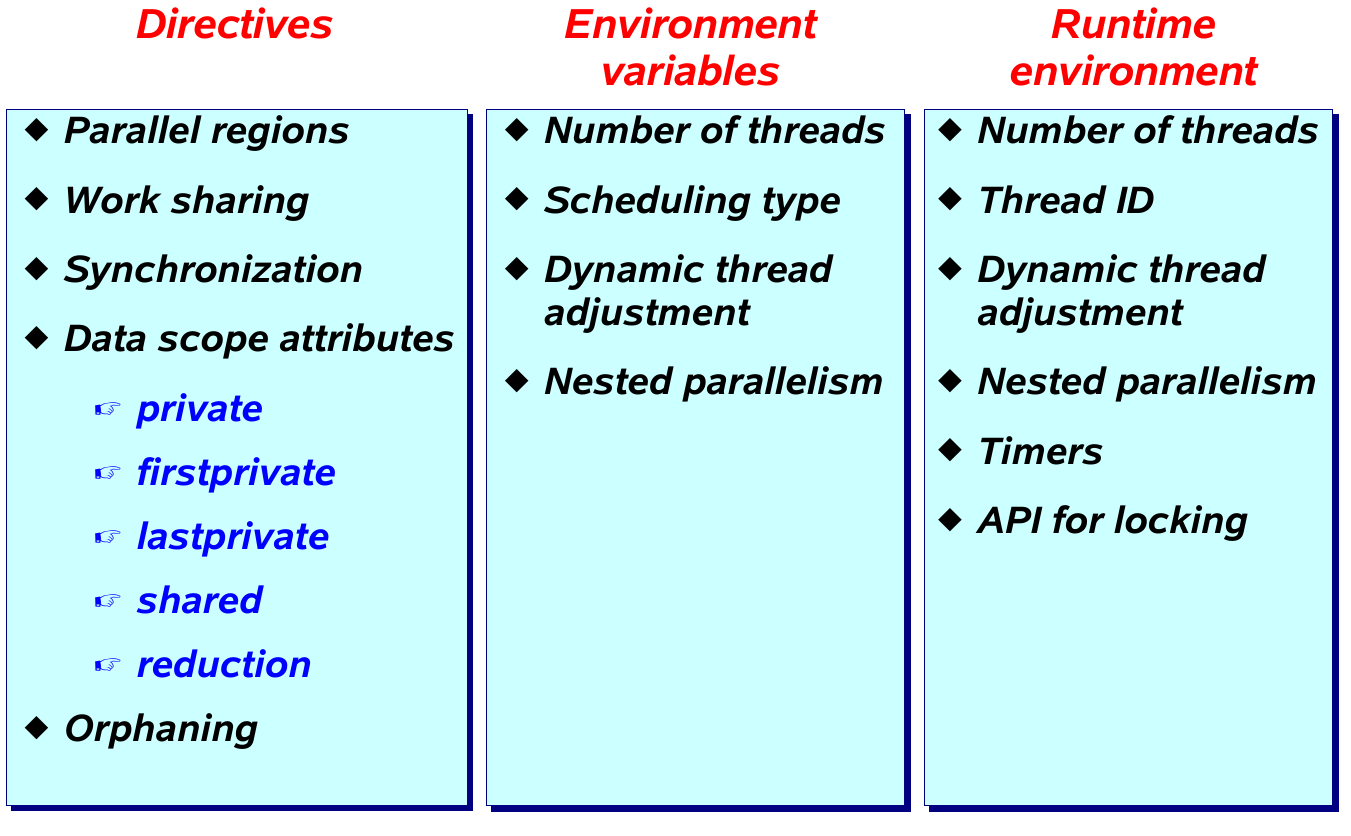
Components of OpenMP
OpenMP Is Not:
- Meant for distributed memory parallel systems (by itself)
- Necessarily implemented identically by all vendors
- Guaranteed to make the most efficient use of shared memory
- Required to check for data dependencies, data conflicts, race conditions, deadlocks, or code sequences that cause a program to be classified as non-conforming
- Designed to handle parallel I/O. The programmer is responsible for synchronizing input and output.
Directive format
#pragma omp directive [clause [clause] ...]
例子:
|
|
Some directives

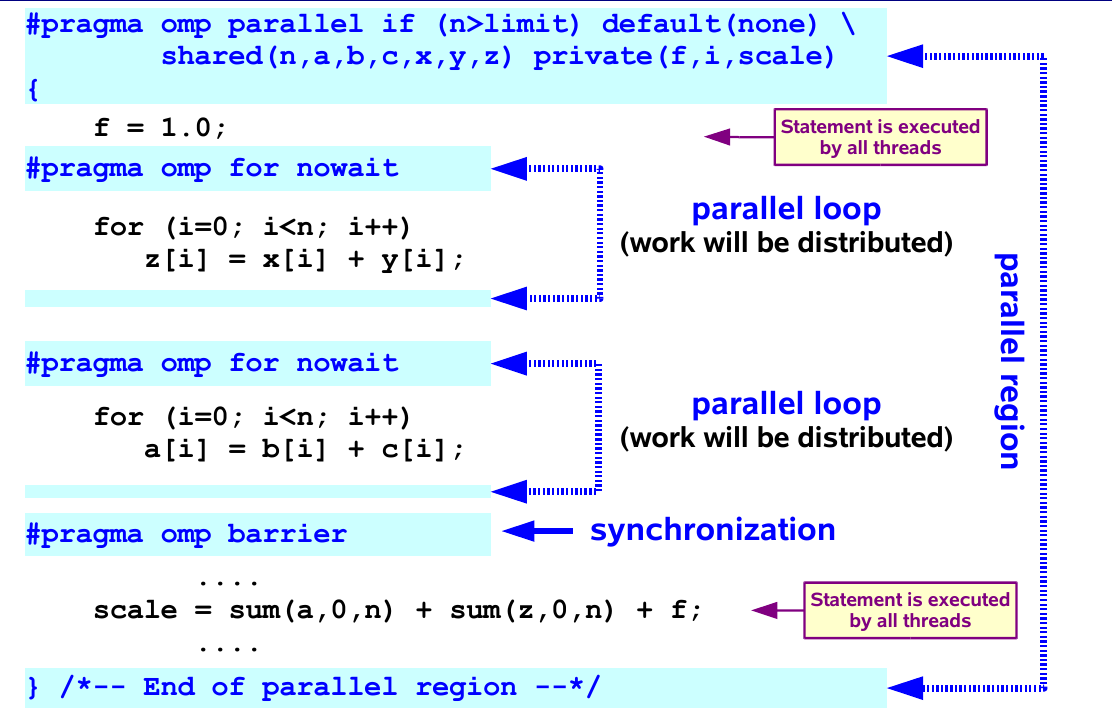
- Private variables are undefined on entry and exit of the parallel region
- The value of the original variable (before the parallel region) is undefined after the parallel region !
- A private variable within a parallel region has no storage association with the same variable outside of the region
- Use the first/last private clause to override this behaviour
Example private variables

 variables declared inside parallel region are private.
variables declared inside parallel region are private.
firstprivate is used to:
- initialize a variable from the serial part of the code
- private clause doesn't initialize the variable
lastprivate
- thread that executes the ending loop index copies its value to the master (serial) thread
- this gives the same result as serial execution
ordered
- used when part of the loop must execute in serial order
- ordered clause plus an ordered directive
|
|
|
|
The collapse clause
When you have nested loops, you can use the collapse clause to apply the threading to multiple nested iterations.
|
|
Sections
Sometimes it is handy to indicate that "this and this can run in parallel". The sections setting is just for that.
|
|
This code indicates that any of the tasks Work1, Work2 + Work3 and Work4 may run in parallel, but that Work2 and Work3 must be run in sequence.
|
|
- If “too many” sections, some threads execute more than one section (round-robin)
- If “too few” sections, some threads are idle
- We don’t know in advance which thread will execute which section
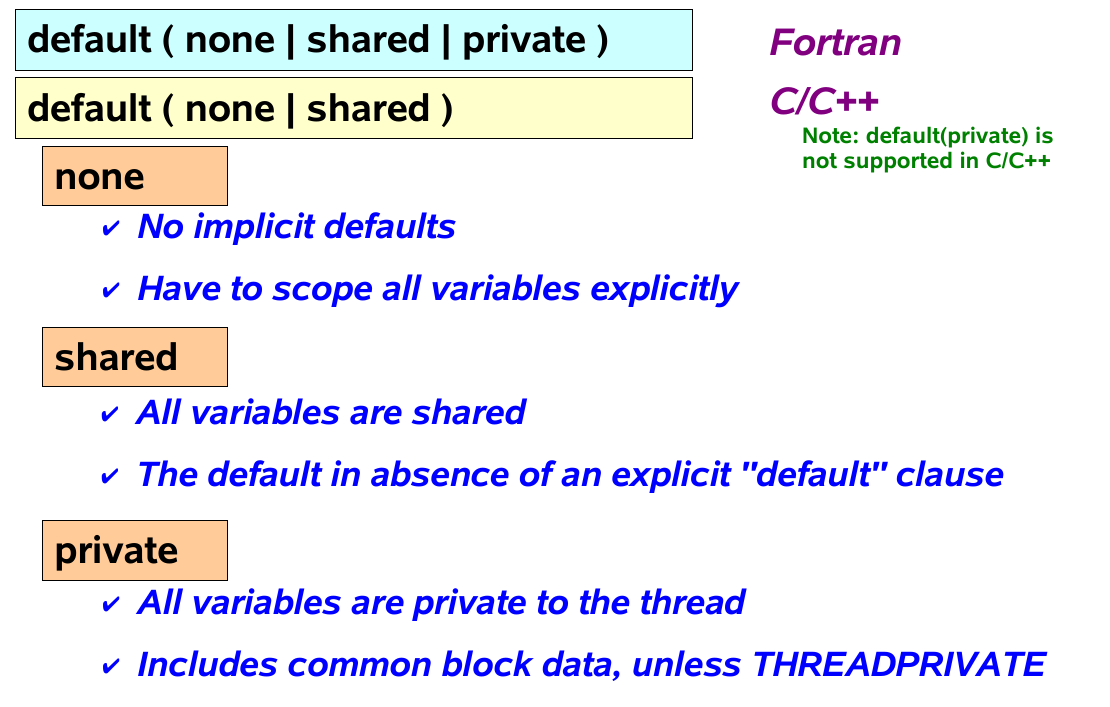
The default clause
The reduction clause

|
|
The nowait clause

The parallel region
 A parallel region supports the following clauses:
A parallel region supports the following clauses:
- if (scalar expression)
- private (list)
- shared (list)
- default (none|shared)
- reduction (operator: list)
- copyin (list)
- firstprivate (list)
- num_threads (scalar_int_expr)
The schedule clause for Load Balance
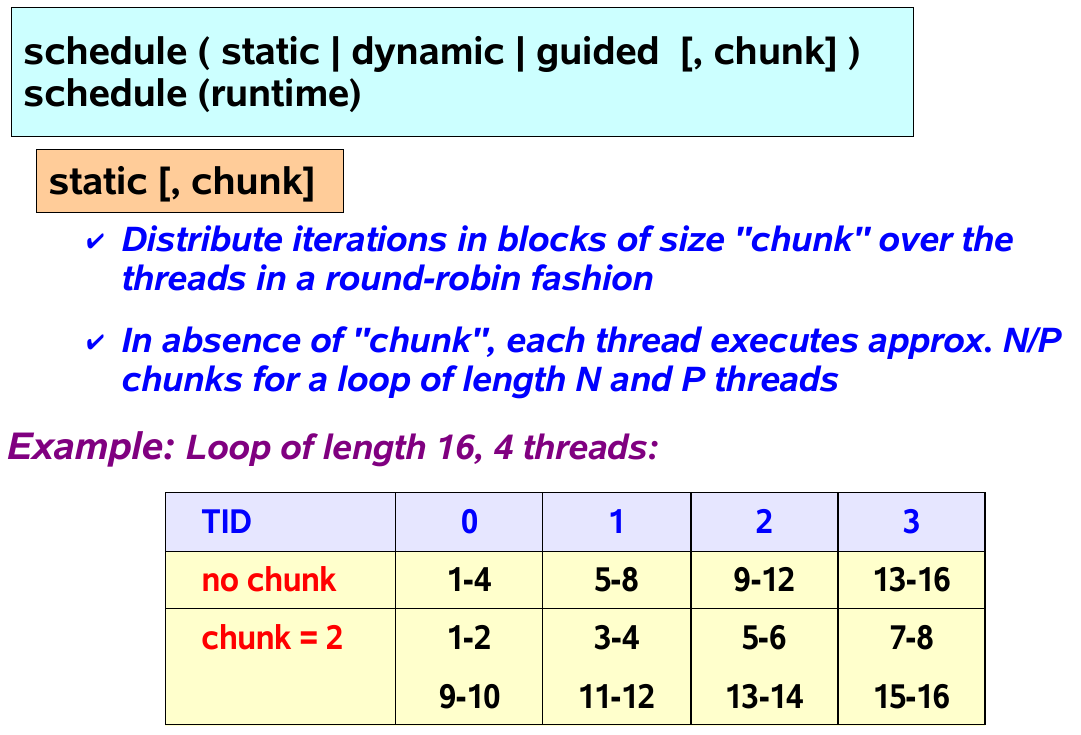

- static: each thread is assigned a fixed-size chunk (default)
- dynamic: work is assigned as a thread request it
- guided: big chunks first and smaller and smaller chunks later
- runtime: use environment variable to control scheduling
Synchronization Controls
MASTER Directive
#pragma omp master newline The MASTER directive specifies a region that is to be executed only by the master thread of the team
#pragma omp barrier
Each thread waits until all others have reached this point
Critical region
All threads execute the code, but only one at a time:
|
|
#pragma omp atomic <statement>
This is a lightweight, special form of a critical section
SINGLE and MASTER construct
|
|
Only one thread in the team executes the code enclosed
|
|
Only the master thread executes the code block
|
|
The enclosed block of code is executed in the order in which iterations would be executed sequentially
|
|
Ensure that all threads in a team have a consistent view of certain objects in memory (In the absence of a list, all visible variables are flushed)
the parallel construct implies a barrier in the end of the parallel region
loop constructsingle constructparallel construct
OpenMP Environment Variables
| OpenMP environment variable | Default for Sun OpenMP |
|---|---|
| OMP_NUM_THREADS n | 1 |
| OMP_SCHEDULE “schedule,[chunk]” | static, “N/P” (1) |
| OMP_DYNAMIC { TRUE|FALSE } | TRUE (2) |
| OMP_NESTED { TRUE | FALSE } | FALSE (3) |
| OMP_STACKSIZE |
OpenMP Runtime Functions
| Name | Functionality |
|---|---|
| omp_set_num_threads | Set number of threads |
| omp_get_num_threads | Return number of threads in team |
| omp_get_max_threads | Return maximum number of threads |
| omp_get_thread_num | Get thread ID |
| omp_get_num_procs | Return maximum number of processors |
| omp_in_parallel | Check whether in parallel region |
| omp_set_dynamic | Activate dynamic thread adjustment (but implementation is free to ignore this) |
| omp_get_dynamic | Check for dynamic thread adjustment |
| omp_set_nested | Activate nested parallelism(but implementation is free ignore this) |
| omp_get_nested | Check for nested parallelism |
| omp_get_wtime | Returns wall clock time |
| omp_get_wtick | Number of seconds between clock ticks |
Summary
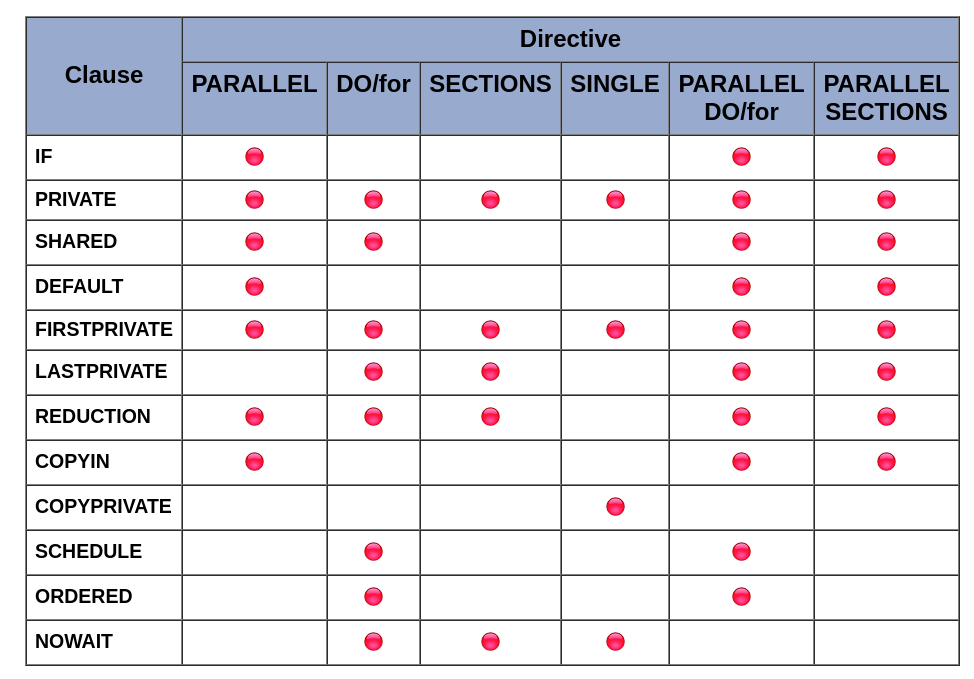
The following OpenMP directives do not accept clauses:
- MASTER
- CRITICAL
- BARRIER
- ATOMIC
- FLUSH
- ORDERED
- THREADPRIVATE
example
- find the max number in an array and get the index
|
|
- Using collapse
|
|
Output:
id 3 k = 2 j = 1
id 0 k = 1 j = 1
id 2 k = 1 j = 3
id 4 k = 2 j = 2
id 1 k = 1 j = 2
id 5 k = 2 j = 3
OpenMP Notes about Acceleration Performance
Eigen Block operation VS OpenMP for operation
|
|
Result
The following results getting from PC make mpitest file=test.cpp n=2
1.
1000000
block operation cost time: 0.0114908 seconds
OpenMP for cost time: 0.0650411 seconds
OpenMP block operation cost time: 0.0261152 seconds
Normal for cost time: 0.134705 seconds
block operation cost time: 0.114225 seconds
OpenMP for cost time: 0.461387 seconds
OpenMP block operation cost time: 0.165431 seconds
Normal for cost time: 1.16467 seconds
We can see that the Eigen block operation for add is much faster that OpenMP implementation.
Compared new operation
|
|
Result
The following result measured based on PC mpirun -n 2
1.
10000 1000
Single thread cost time: 0.0245256 seconds
OpenMP cost time: 0.0420988 seconds
100000 1000
Single thread cost time: 0.237885 seconds
OpenMP cost time: 0.270465 seconds
1000000 100
Single thread cost time: 1.67924 seconds
OpenMP cost time: 14.3786 seconds
From the result, we can see that while using new operation, single thread is better than multi-threads.