Double Buffering
Double buffering is a term used to describe a device with two buffers. The usage of multiple buffers increases the overall throughput of a device and helps prevents bottlenecks. For example, with graphics, double buffering can show one image or frame while a separate frame is being buffered to be shown next. This method makes animations and games look more realistic than the same done in a single buffer mode.
Cache Blocking
An important class of algorithmic changes involves blocking data structures to fit in cache. By organizing data memory accesses, one can load the cache with a small subset of a much larger data set. The idea is then to work on this block of data in cache. By using/reusing this data in cache we reduce the need to go to memory (reduce memory bandwidth pressure. The key idea behind blocking is to exploit the inherent data reuse available in the application by ensuring that data remains in cache across multiple uses.
In terms of code change, blocking typically involves a combination of loop splitting and interchange. In most application codes,
Original Source:
|
|
In this example, data (body2) is streamed from memory. Assuming NBODIES is large, we would have no reuse in cache. This application is memory bandwidth bound. The application will run at the speed of memory to CPU speeds, less than optimal.
Modified Source (with 1-D blocking):
|
|
In this modified code, data (body22) is kept and reused in cache, resulting in better performance. If BLOCK is chosen such that this set of values fits in cache, memory traffic is brought down by a factor of BLOCK.
Example:
|
|
normal cost time: 10503367
cache blocking cost time: 9575784
Keep Memory
In order to avoid unnecessary reallocation and release, we can keep some reused parameters (such as modle parameters) in the core memory.
Memory Coalescing and cache utilization
Main memory gets loaded via cache line chunks - usually 64 or 128 bytes - through a hierarchy of caches: from DRAM to L3 to L2 and L1 and finally to the CPU registers.Modern cache sizes have increased significantly, and we can have around 35MB of space in L3 cache shared with all the processors. Reading from L3 cache is approximately 3x faster than from DRAM.
In order to utilizing this feature, we should removing data memory fragmentation. The following are some examples:
-
While facing sparse input vectors or matrix, we can create one long contiguous vector that consecutively stores non-zero indices and values. To keep track of variable numbers of non-zeros, we keep another vector of offsets.
-
In neural networks, the neuron weights in the same layer can be located contiguously in the main memory increasing cache efficiency.
Hyper-threading
Hyper-Threading allows the processor to virtually double its number of cores and execute twice as many threads simultaneously, jumping back and forth between threads to execute instructions for one whenever the other is stalled.
- If the program need randomly access the memory, threads do get stalled due to cache miss. At that point, hyper-threading will be favorable because another thread can utilize the wait time to process a different data instance.
Vectorization
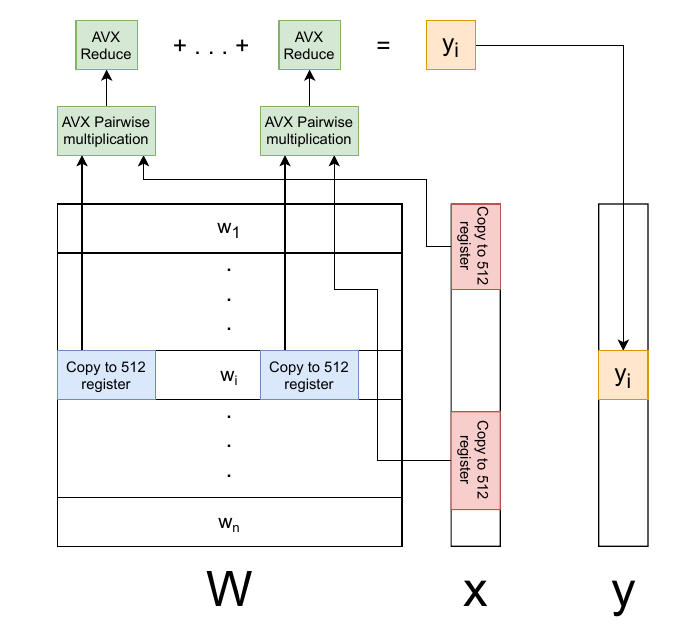
Matrix-vector multiplication, matrix in store in row-major.
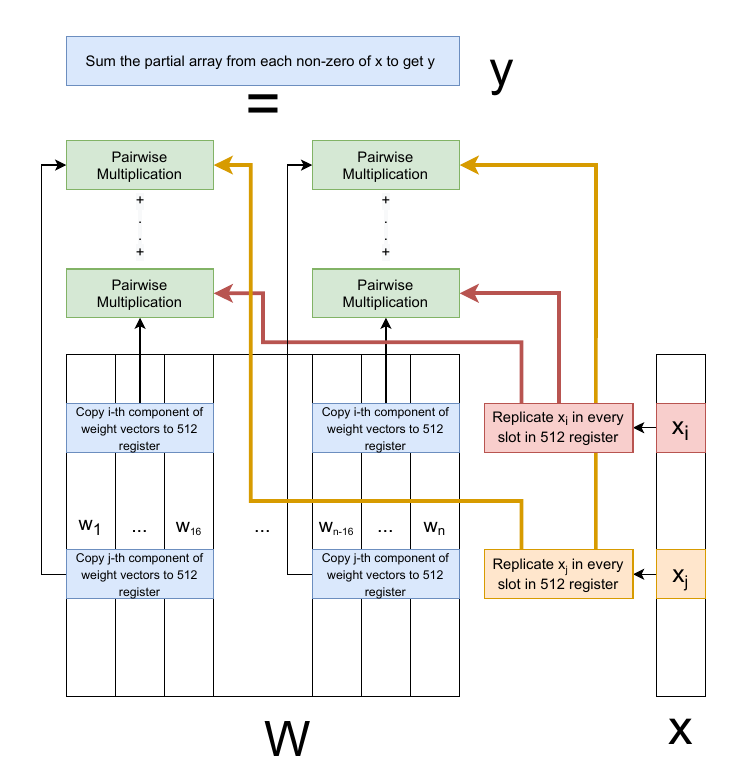
Matrix-vector multiplication, matrix in store in column-major.
Memory Reuse
To reduce the memory allocate and destroy.
Branch Prediction
|
|
After sort the array the time cost is: 5 s
Without sort the time cost is: 15 s
The reason is than the CPU using branch predition strategy, after sort could increase the branch prediction accuracy.
We could replace the conditional branch by some hack skill, eg..
|
|
NUMA-aware
Reference
- Introduction to Instruction Scheduling
- Memory Optimizations
- Accelerating SLIDE Deep Learning on Modern CPUs: Vectorization, Quantizations, Memory Optimizations and More
- SLIDE : IN DEFENSE OF SMART ALGORITHMS OVER HARDWARE ACCELERATION FOR LARGE -SCALE DEEP LEARNING SYSTEMS
- NUMA-Caffe: NUMA-Aware Deep Learning Neural Networks