DiSC Algorithm[1,2]
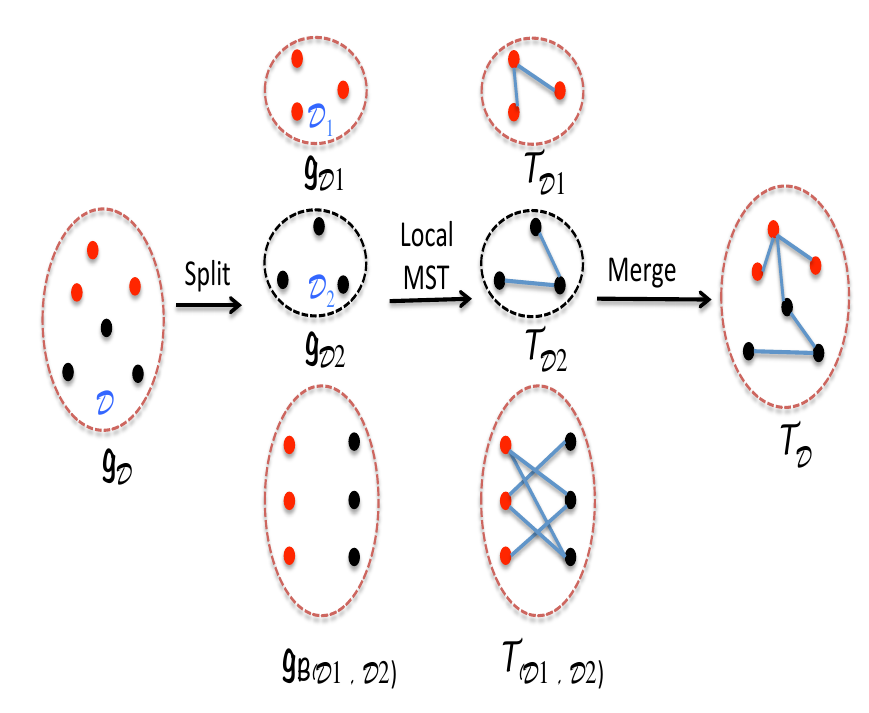
- 首先将数据集分成 s 等分,对于这 s 个小数据集,我们构建全连接图 (complete graphs)。
- 之后我们对于这 s 个数据集两两配对形成 $C_s^2$ 个数据集,基于这些数据集,我们构建二分图 (bipartite graph)。
- 对于这两种类型的图,我们都求解一个 local 的最小生成树 (MST, minimum spanning tree)。
- 最后合并这 $s + C_s^2$ 个最小生成树,生成一个全局的 MST,通过这个 MST,我们即可得到 hierarchical clustering 所需的 dendrogram 。

根据一个进程处理一个任务来算的话,存在限制条件 $s + C_s^2 < n$ , n 为进程数量。
- 100个进程只能处理 13 等分
- 1000 个进程只能处理 44 等分
- 10000 个进程只能处理 140 等分
该方法的缺点在于所能处理的数据量规模受限制,对于切分后 s 等分数据,数据量的大小不能超过一个进程所能拥有内存大小的一半。