Basis
- Ray runtime:
The Ray runtime consists of multiple services/processes started in the background for communication, data transfer, scheduling, and more. The Ray runtime can be started on a laptop, a single server, or multiple servers.
- Creating an actor
An actor is essentially a stateful worker (or a service). When a new actor is instantiated, a new worker is created, and methods of the actor are scheduled on that specific worker and can access and mutate the state of that worker.
|
|
equivalent to the following:
|
|
call methods
|
|
Run Test
- test 1
|
|
结果是只有一个 CPU 在执行任务占用率为 100% . 但是会出现有很多 Ray::IDLE 的进程
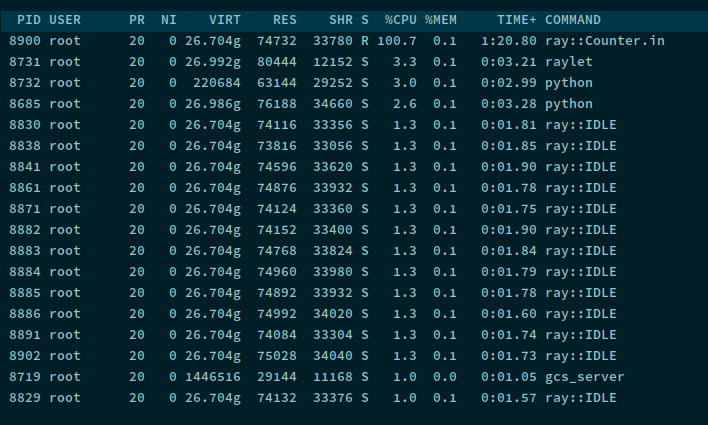 感觉直接
感觉直接 @ray.remote(num_cpus=3) 并没有什么效果。且这里的死循环,CPU 占用 100% 并不是单独使用一个 CPU, 而是使用了多个 CPU , 且使用哪几个 CPU 并不确定一直在变化。
- test 2
|
|
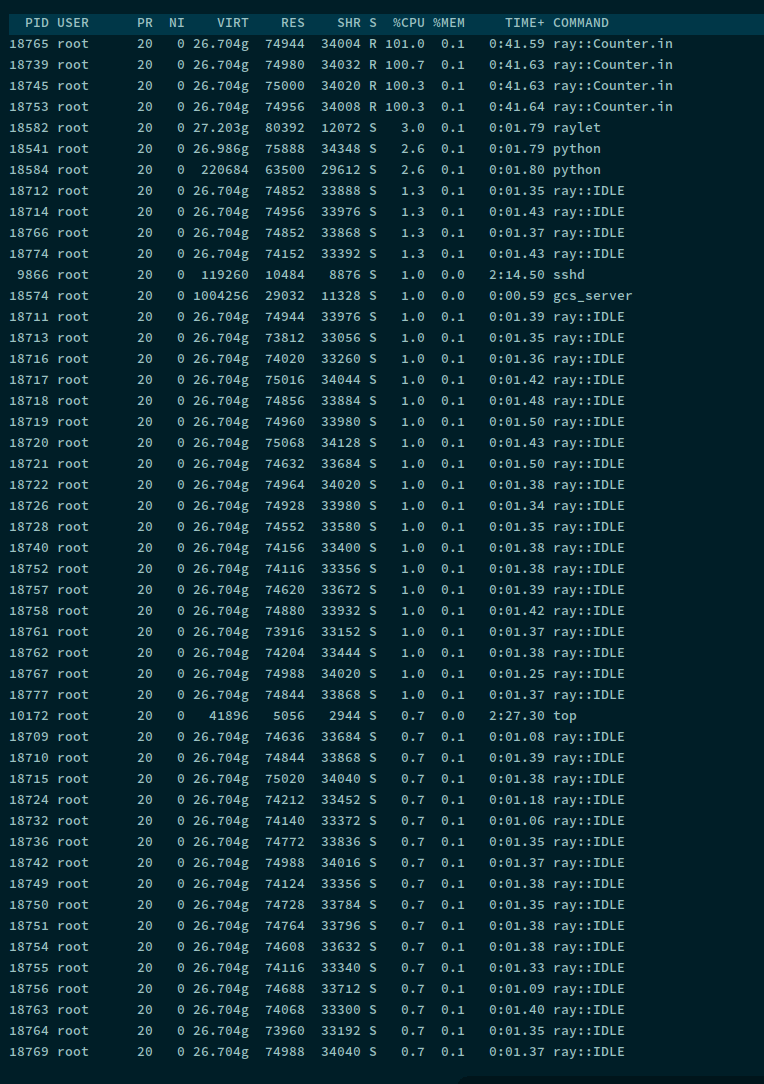
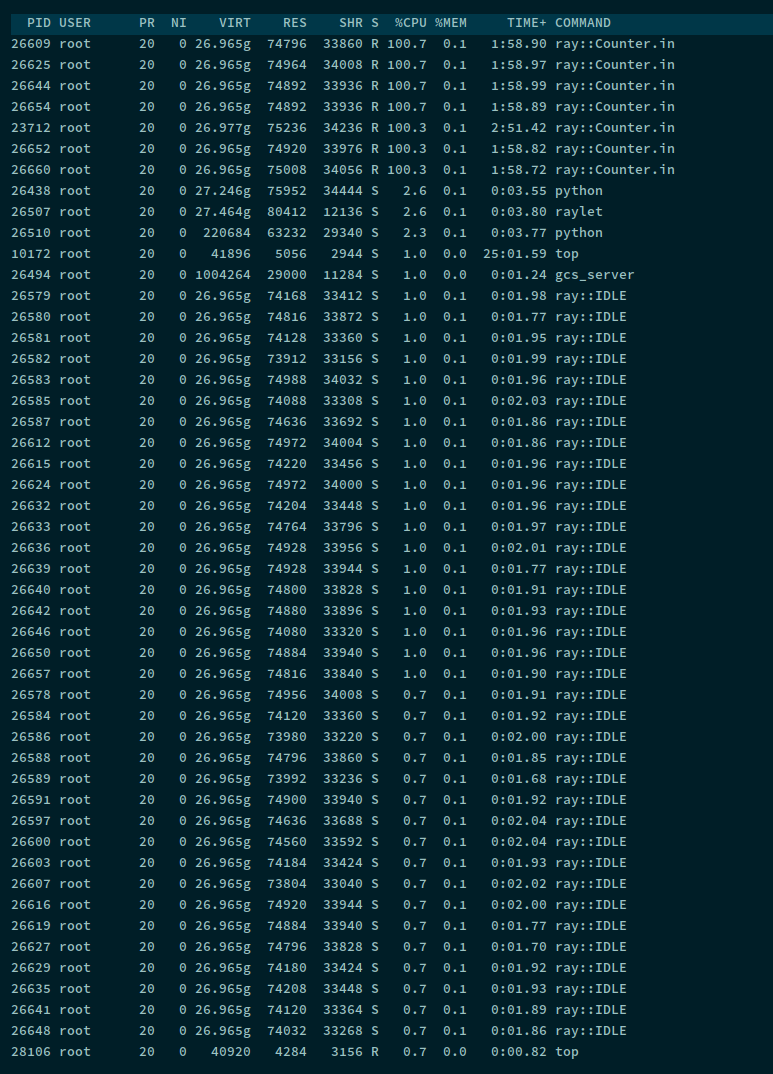
 可知各个执行任务的 worker 进程是由 raylet 进程生成的,生成的 worker 进程的数量等于节点 cpu 的核数。通过
可知各个执行任务的 worker 进程是由 raylet 进程生成的,生成的 worker 进程的数量等于节点 cpu 的核数。通过 ray.init(num_cpus) 可以控制生成 worker 进程的数量。
 可看出 IDLE 的 worker 也得占用 73 M 左右的内存
可看出 IDLE 的 worker 也得占用 73 M 左右的内存
- test 3
|
|
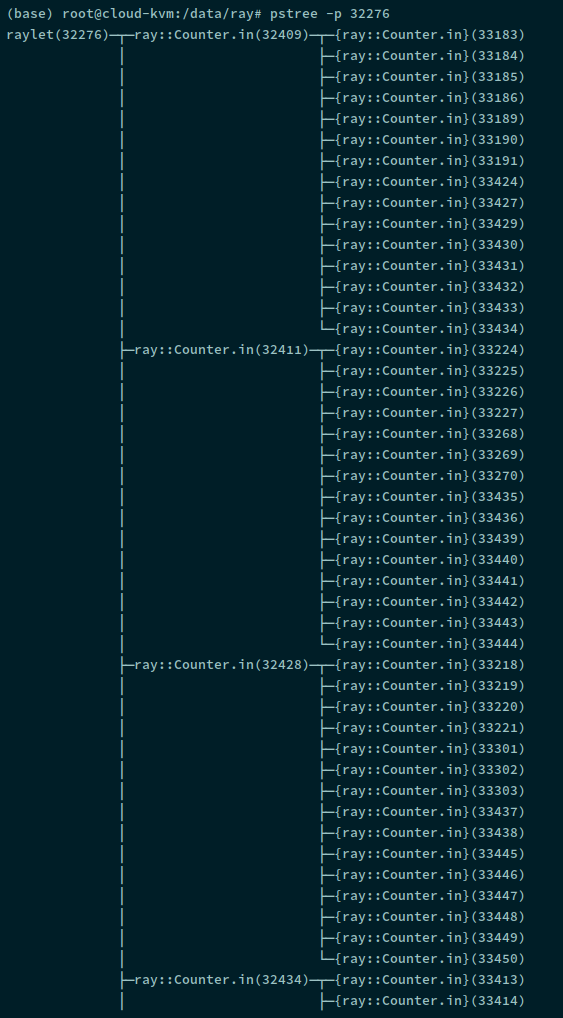
 输出的结果显示执行整个程序的代码的进程为
输出的结果显示执行整个程序的代码的进程为 python (python test.py) . 该进程的子进程有
raylet: 执行的是在/tmp/ray/session**/sockets/目录下的 raylet 程序 (该目录下还有个 plasma_store 程序)python_2: 执行/python/ray/_private/log_monitor.pypython_3: 执行/python/ray/autoscaler/_private/monitor.pygcs_serverredis-serverredis-server
由上可得出其进程关系图为:
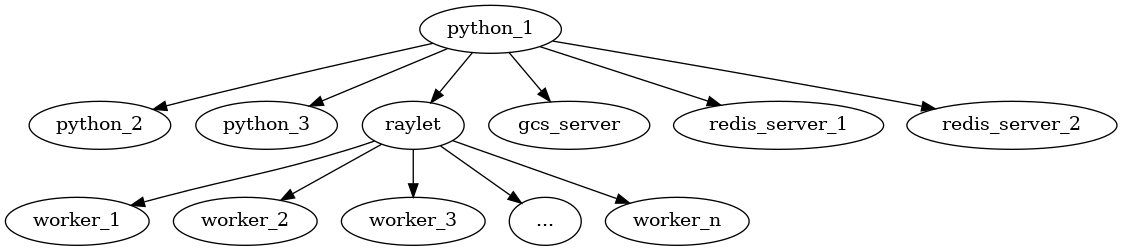
- plot_pong_example.py
使用的 actor 个数为 10. 通过分析 ray 输出的 log 文件可得以下信息:
Source Code Note
worker.py

worker has three mode;
- SCRIPT_MODE: should be used if this Worker is a driver that is being run as a Python script or interactively in a shell. It will print information about task failures.
- WORKER_MODE should be used if this Worker is not a driver. It will not print information about tasks.
- LOCAL_MODE should be used if this Worker is a driver and if you want to run the driver in a manner equivalent to serial Python for debugging purposes. It will not send remote function calls to the scheduler and will instead execute them in a blocking fashion.
Import functions:
remote(*args, **kwargs)
|
|
This function do nothing import, it just parse arguments and call function make_decorator().
make_decorator().
|
|
This function define a nested function decorator(). The decorator() function check parameter function_or_class is function or a class,
- if is function just call function
ray.remote_function.RemoteFunction(). - if is class just call function
ray.actor.make_actor()
The function make_decorator() just return nested function decorator()
Q: where is the function_or_class come from?
In function nested function decorator(), add code print("Add by liudy", function_or_class).
- test code
|
|
result:
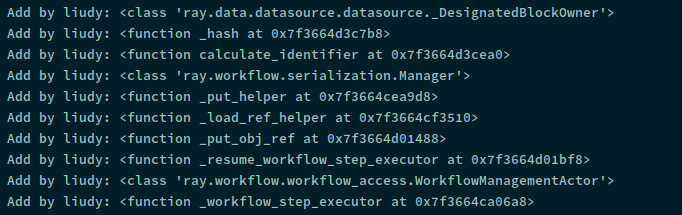 just using
just using ray.init() the function decorator() is called by 10 times
<class 'ray.data.datasource.datasource._DesignatedBlockOwner'>
|
|
<function _hash at 0x7f3664d3c7b8>
|
|
<function calculate_identifier at 0x7f3664d3cea0>
|
|
<class 'ray.workflow.serialization.Manager'>
|
|
- test code
|
|
result:
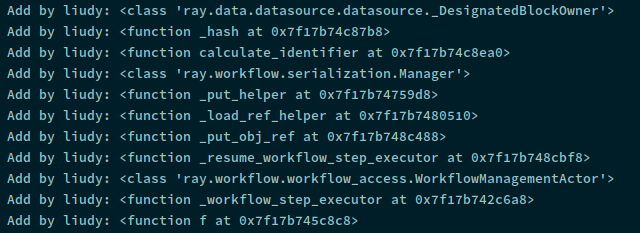
@ray.init()
locate worker.py
gcs_server 是一个编译好的程序,位于 /ray/python/ray/core/src/ray/gcs
通过使用 subprocess.Popen 来创建子进程
|
|
redis server 通过使用位于 /data/ray/ray/python/ray/core/src/ray/thirdparty/redis/src 的 redis-server 程序
|
|
start monitor 通过 cmd 调用 python monitor.py 执行
|
|
start ray client server 通过 cmd 调用 python
|
|
start redis client 位于 /data/ray/ray/python/ray/core/src/ray/thirdparty/redis/src/ 下的程序 redis-cli
|
|
start raylet (combined local scheduler and object manager.), 运行位于 ray/python/ray/core/src/ray/raylet/ 的 raylet 程序, 调用 raylet 程序的终端命令为:
|
|
其中开启多个 worker 进程的命令为, 开启多少个 worker 设置为 --maximum_startup_concurrency=10
--python_worker_command=/usr/bin/python /data/ray/ray/python/ray/workers/setup_worker.py /data/ray/ray/python/ray/workers/default_worker.py --node-ip-address=10.186.115.19 --node-manager-port=RAY_NODE_MANAGER_PORT_PLACEHOLDER --object-store-name=/tmp/ray/session_2021-12-07_14-51-20_860909_63031/sockets/plasma_store --raylet-name=/tmp/ray/session_2021-12-07_14-51-20_860909_63031/sockets/raylet --redis-address=10.186.115.19:6379 --temp-dir=/tmp/ray --metrics-agent-port=41628 --logging-rotate-bytes=536870912 --logging-rotate-backup-count=5 RAY_WORKER_DYNAMIC_OPTION_PLACEHOLDER --redis-password=5241590000000000',
|
|
start head processes (node.py)
|
|
start redis_servers (node.py)
|
|
core_worker.h
class CoreWorker, 在构造函数中
- 初始化 task receivers, raylet client,
- start a rpc server
- Initialize gcs client
- Initialize profiler
- Start IO thread
TaskSpecification class
location: task_spec.h
FunctionDescriptorInterface class
- function_descriptor.h
|
|
PythonFunctionDescriptor class, 通过 RPC 接收来的 rpc::FunctionDescriptor messag 包含了四个信息: module_name, class_name, function_name, function_hash
message PythonFunctionDescriptor {
string module_name = 1;
string class_name = 2;
string function_name = 3;
string function_hash = 4;
}
|
|
notes
- 在 function_descriptor.pxi 里有封装 python 函数和类的类
PythonFunctionDescriptor - 在
_raylet.pyx里有对 CoreWorker 的实现和赋值 - FunctionDescriptor 的定义
|
|
- 对于 python task 执行的代码
|
|
获取 python 任务
|
|
其中 execution_info 是从一个字典execution_infos中获取的
|
|
所以这个 function_actor_manager 是什么呢?
|
|
所以其是一个FunctionActorManager类 (在 FunctionActorManager 类中其将 actor class 和 function 用 pickle 序列化后将其保存至 redis。)
|
|
在该类中 execution_infos 就是一个空的字典
|
|
所以这个 execution_infos 里面到底保存了什么东西呢?
|
|
可知其中保存的是 get_execution_info 函数的返回值,
|
|
其中 _function_execution_info 定义如下;
|
|
其中 FunctionExecutionInfo 是一个 nametuple
|
|
gym
|
|
The step function will returns four values:
- observation (object): an environment-specific object representing your observation of the environment. For example, pixel data from a camera, joint angles and joint velocities of a robot, or the board state in a board game.
- reward (float): amount of reward achieved by the previous action. The scale varies between environments, but the goal is always to increase your total reward.
- done (boolean): whether it’s time to reset the environment again. Most (but not all) tasks are divided up into well-defined episodes, and done being True indicates the episode has terminated. (For example, perhaps the pole tipped too far, or you lost your last life.)
- info (dict): diagnostic information useful for debugging. It can sometimes be useful for learning (for example, it might contain the raw probabilities behind the environment’s last state change). However, official evaluations of your agent are not allowed to use this for learning.
Every environment comes with an action_space and an observation_space. These attributes are of type Space, and they describe the format of valid actions and observations:
|
|
The Discrete space allows a fixed range of non-negative numbers, so in this case valid actions are either 0 or 1. The Box space represents an n-dimensional box, so valid observations will be an array of 4 numbers. We can also check the Box’s bounds:
|
|