Methods
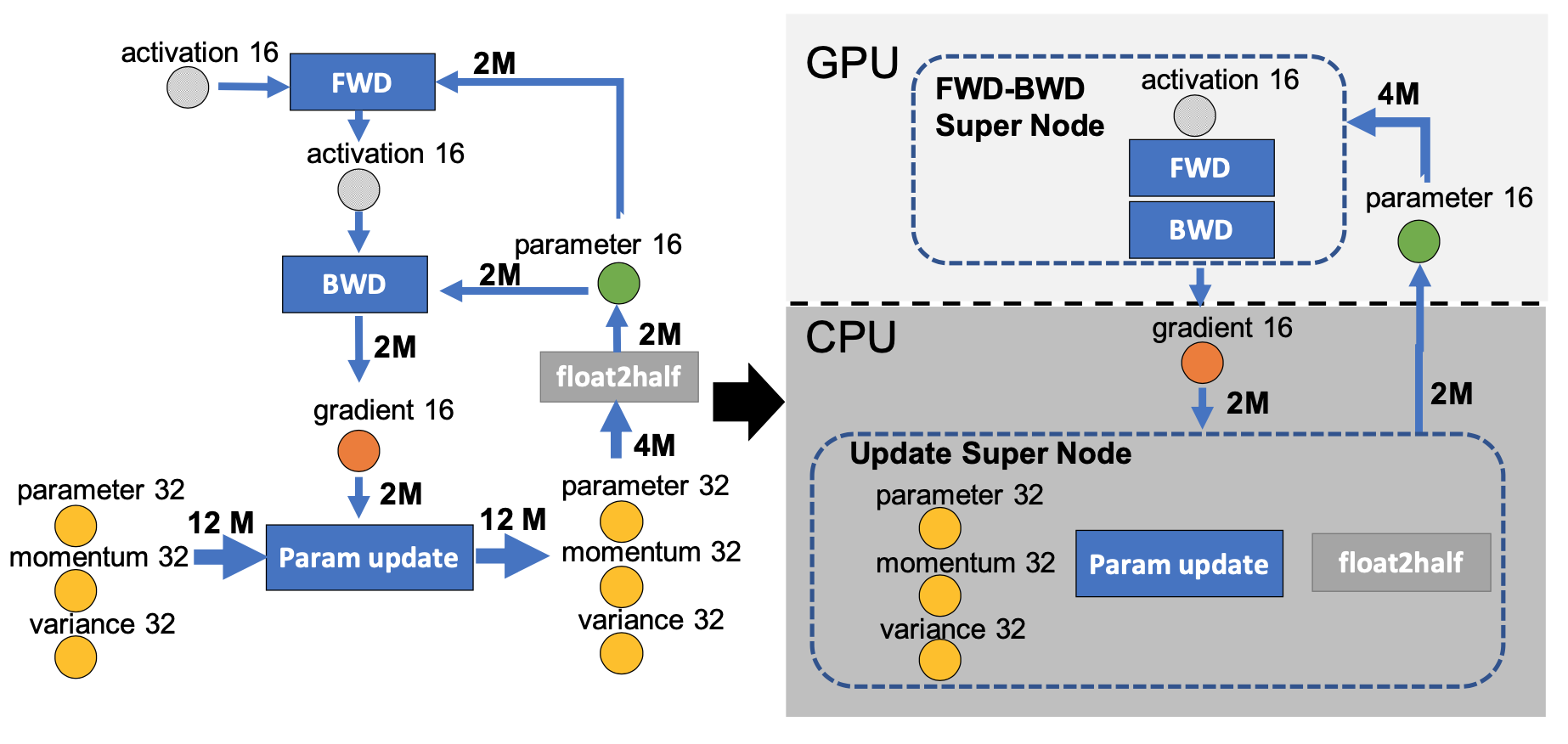 We offload the gradients, optimizer states and optimizer computation to CPU, while keeping the parameters and forward and backward computation on GPU.
We offload the gradients, optimizer states and optimizer computation to CPU, while keeping the parameters and forward and backward computation on GPU.
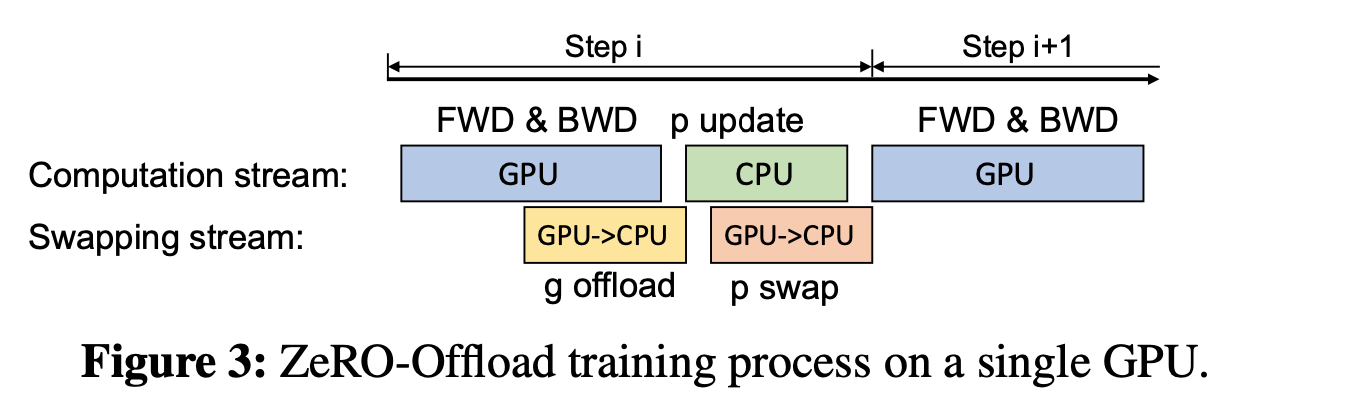 The communication time between GPU->CPU or CPU->GPU are overlap with computation time.
The communication time between GPU->CPU or CPU->GPU are overlap with computation time.
scaling to Multi-GPUs
ZeRO-Offload partitions gradients and optimizer states among different GPUs, and each GPU offloads the partition it owns to the CPU memory and keeps it there for the entire training. During the backward propagation, gradients are computed and averaged using reduce-scatter on the GPU, and each GPU only offloads the averaged gradients belonging to its partition to the CPU memory. Once the gradients are available on the CPU, optimizer state partitions are updated in parallel by each data parallel process directly on the CPU. After the update, parameter partitions are moved back to GPU followed by an all-gather operation on the GPU.
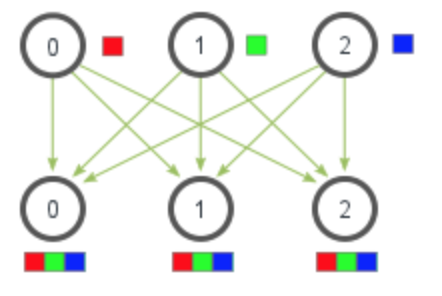
reduce-scatter operation as follow:
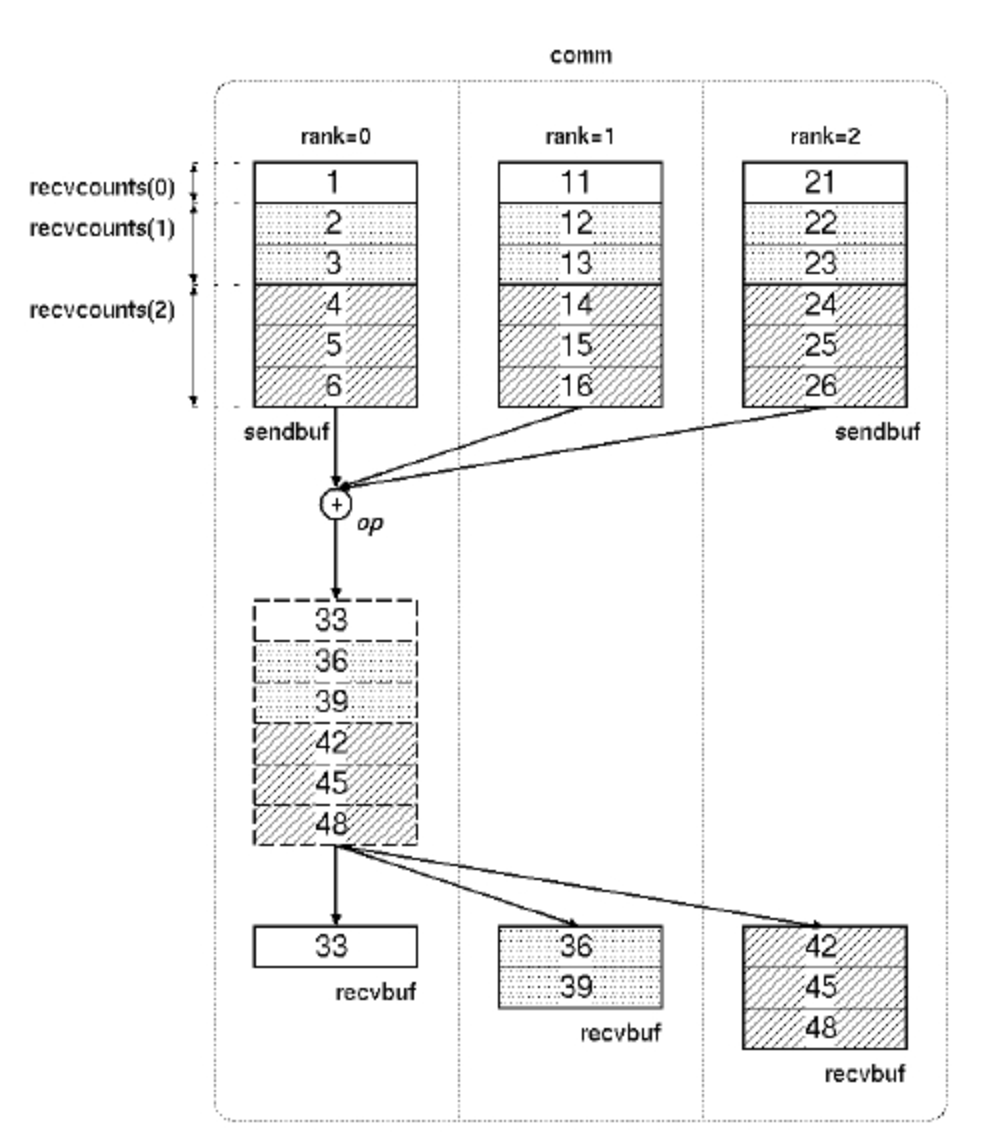
all-gather operation as follow: